Paul Hammant's Blog: 'Old-School' Merkle Trees Rock An instead-of-blockchain implementation choice
Blockchains have a huge amount of interest these days. Before blockchains, though, there were much simpler Merkle trees solutions. They are underrated today, and after this quick primer, you might consider them for solutions you’re engineering instead of blockchains.
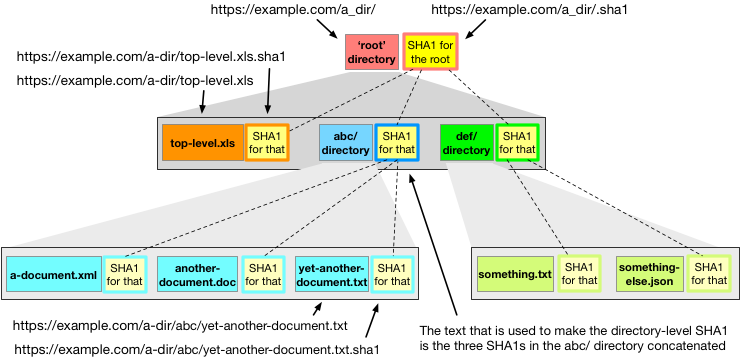
^ a depiction of a directory structure of files and sha1 hashes. I don’t like standard the depiction of Merkle trees on the web (2 split into two which are split into two…), this one has deliberately irregular content and shows hashes as separate files. In this pic, I’m also using Web URLs to hint at how clients would use the tree from afar. Of course, URLs appear to have a directory structure that maps to a file system. That’s not a contract as such, and many web applications online would create a directory structure for URLs when all the content is in a relation schema (flat). Similarly, web-applications may flatten a real directory structure on a file system and hide it completely from the user in the browser. To me though I prefer URLs representative of how things are stored.
Hypothetical application: Hot updating of voting data during US presidential elections.
All the municipalities, counties and states update central records as election night progresses. News organizations and anyone that cares subscribes to the nodes that interest them waiting for a SHA1 to change. It is centralized because there are 3141 such districts in the US. If you have the URL for the node that interests you then polling every 30 seconds to see if a 16-character string has changed isn’t irresponsible.
As we like the URL subscription mode, we will design a directory structure that is easy to understand. Here’s a subset showing some New York and Ohio counties:
./N/NY/W/Wyoming_County/36121.json
./N/NY/Y/Yates_County/36123.json
./O/OH/A/Adams_County/39001.json
./O/OH/A/Allen_County/39003.json
The number is a Federal Information Processing Standards (FIPS) number for that voting area. It doesn’t feel hugely necessary for east coast states, but for Alaska where there are no named counties, then it makes a lot of sense. Here’s my source data. The top few rows show the Alaska ‘problem’. Note this is election data from 2016. Spoiler alert: We’ll have to wait a few more years to find out if Trump is a two-term president or not.
You could argue that the intermediate directories I have made are overkill. Perhaps that is true, but let’s pretend this is a far bigger (wider and deeper) system than 3141 records.
When we merkelize those records we end up with:
./.sha1
./N
./N/.sha1
./N/NY
./N/NY/.sha1
./N/NY/W
./N/NY/W/.sha1
./N/NY/W/Wyoming_County
./N/NY/W/Wyoming_County/.sha1
./N/NY/W/Wyoming_County/36121.json
./N/NY/W/Wyoming_County/36121.json.sha1
./N/NY/Y
./N/NY/Y/.sha1
./N/NY/Y/Yates_County
./N/NY/Y/Yates_County/.sha1
./N/NY/Y/Yates_County/36123.json
./N/NY/Y/Yates_County/36123.json.sha1
./O
./O/.sha1
./O/OH
./O/OH/.sha1
./O/OH/A
./O/OH/A/.sha1
./O/OH/A/Adams_County
./O/OH/A/Adams_County/.sha1
./O/OH/A/Adams_County/39001.json
./O/OH/A/Adams_County/39001.json.sha1
./O/OH/A/Allen_County
./O/OH/A/Allen_County/.sha1
./O/OH/A/Allen_County/39003.json
./O/OH/A/Allen_County/39003.json.sha1
^ that is a simple directory representation - not the order of creation of the SHA1 hashes.
So I have some Python that takes the CSV and makes the directory structure and the JSON files that contain the numbers/percentages.
I have a second Python script that calculated the SHA1. That is depth-first in order to be efficient. It just runs forever - recalculating SHA1 hashes in a loop. When it has warmed up, and nothing is changing it takes 4 seconds to traverse the whole tree.
I have lines printing out the SHA1s that have just been (re)generated. You might not do that in a production version of the same, but it helps explain what is going on here. This snipped from then of the generation of 7142 Merkle tree hashes:
Updating: data/W/WY/W/Washakie_County/56043.json.sha1
Updating: data/W/WY/W/Washakie_County/.sha1
Updating: data/W/WY/W/Weston_County/56045.json.sha1
Updating: data/W/WY/W/Weston_County/.sha1
Updating: data/W/WY/W/.sha1
Updating: data/W/WY/.sha1
Updating: data/W/.sha1
Updating: data/.sha1
Updates: 7142, root SHA1: 33cf709e348a0bf57686ddc60398f755e9783517, duration: 44.2s
Updates: 0, root SHA1: 33cf709e348a0bf57686ddc60398f755e9783517, duration: 18.1s
Updates: 0, root SHA1: 33cf709e348a0bf57686ddc60398f755e9783517, duration: 9.6s
Updates: 0, root SHA1: 33cf709e348a0bf57686ddc60398f755e9783517, duration: 4.1s
^ you can see it reached stability after the first run through. Specifically the last three lines of zero hash (re)creations.
Here’s me creating a new municipality for voting (Zach Galifianakia, Wyoming), while that process to regenerate Merkle-tree hashes keeps running:
Updates: 0, root SHA1: 33cf709e348a0bf57686ddc60398f755e9783517, duration: 4.3s
Updates: 0, root SHA1: 33cf709e348a0bf57686ddc60398f755e9783517, duration: 4.8s
Updates: 0, root SHA1: 33cf709e348a0bf57686ddc60398f755e9783517, duration: 4.6s
Updating: data/W/WY/Z/Zach_Galifianakia/.sha1
Updating: data/W/WY/Z/.sha1
Updating: data/W/WY/.sha1
Updating: data/W/.sha1
Updating: data/.sha1
Updates: 5, root SHA1: e2e07a2a00a7cd1cff53382b5e6d7616aa22217b, duration: 5.5s
Updates: 0, root SHA1: e2e07a2a00a7cd1cff53382b5e6d7616aa22217b, duration: 4.9s
Updating: data/W/WY/Z/Zach_Galifianakia/96572.json.sha1
Updating: data/W/WY/Z/Zach_Galifianakia/.sha1
Updating: data/W/WY/Z/.sha1
Updating: data/W/WY/.sha1
Updating: data/W/.sha1
Updating: data/.sha1
Updates: 6, root SHA1: 98b69473c66e3870aa4bd04a4f22291444754730, duration: 4.5s
Updates: 0, root SHA1: 98b69473c66e3870aa4bd04a4f22291444754730, duration: 3.9s
Updates: 0, root SHA1: 98b69473c66e3870aa4bd04a4f22291444754730, duration: 4.3s
^ first I created the directory. Then a few seconds later I created the JSON record.
This sequence should give you the gist of the simple centralized Merkle tree solution. Note how it updates “depth first”.
What I have coded is a brute-force solution. You could implement a leaner solution by utilizing a file watcher and a queue. Maybe Python is the wrong language too. Go might be a better choice for this for performance reasons.
All the source is in the Github project: CSV starting data, and two Python scripts.
The takeaway?
Although blockchains also use Merkle trees within their implementations, you can use Merkle trees in solutions without that being a blockchain itself. You should also beware of groups telling you that you need to use blockchains when a plain/vanilla (centralized) Merkle tree solution would have been fine.
Commodity implementations (tangential thought)
Git and Mercurial are specialized Merkle-tree solutions that allow a full clone of the tree from some centralized place.
While being de-decentralized VCS solutions, they are most often used in a configuration where the ‘forks’ track a single
canonical online URL-addressable repo. While these two use a Merkle-tree for their internal operation, it’s not in the way outlined above.
It is also not that accessible to end users. The SHA1 hashes are on content AND a decent amount metadata (including DAG related stuff -
ancestors and all that), meaning you could not recreate them by hand with a simple sha1sum invocation from bash.
Subversion is also a specialized Merkle-tree solution. It is pretty similar to Git and Mercurial, except in client use as it has a diminished capability if it is not connected with the server. Straight changing of files is perfectly possible offline, but all history-centric operations require an online connection. Like Git and Mercurial the Merkle-tree is and internal function, but with some futzing of configuration, you can use it from the client side over HTTP(S).
History is important when you want to audit changes over time. With or without history, you’re able to verify the entire tree from the client side using the out of the box features of Merkle trees.
Apache’s Cassandra uses old-school Merkle trees too, internally: read their anti-entropy page if you like.