Paul Hammant's Blog: The number of pre-production environments
Companies that deploying an application or service have a single live environment. There is a range of choices for non-live or pre-production environments though. Environments that developers busy themselves in, QAs test or automate in, and that business-side colleagues sign off changes in are the classic pre-production types.
What I have observed is ‘how many’ and ‘what ones’ and ‘how constructed’ are coupled to the cadence that the larger team has achieved.
From my popular Trunk correlated practices chart:

^ note the logarithmic scale
One release every hundred days (1/100)
Ignoring everything else correlated with this cadence, the team is likely to have a few strongly named environments:
| Environment Name | # | Type | $ | Deploy Freq. | Deploy-ers | Users | Purpose | Comprom-ises |
|---|---|---|---|---|---|---|---|---|
| “Integration” | 1 | multi-machine | 1 | 1-5 a day | all devs | all devs | where developers wait in turn to deploy their compiled code during actual development, (pre commit) | shared downstack services |
| “QA” | 1 | multi-machine | 1.3x | daily | all devs | devs, QA | Where QAs manually test code, and poss. also kick-off automation manually (post commit) | shared downstack services |
| “UAT” | 1 | multi-machine | 1.5x | on demand | Ops | users | where sign off happens, with more deployments closer to release | |
| “Staging” | 1 | a few machines | 0.5x | on demand | Ops | users | where code is deployed on a production database, but to insiders only and ready for a cutover | shares prod infra by design |
One hundred releases every day (100/1)
| Environment Name | # | Type | $ | Deploy Freq. | Deploy-ers | Users | Purpose | Facilitators |
|---|---|---|---|---|---|---|---|---|
| developer laptop or workstation | 1 per dev | n/a | 0.01x | tens a day (each) | 1 dev | 1 dev | where developers privately test their in-progress work | comprehensive service virtualization |
| per developer VM | as above | microcosm | 0.01x | tens a day (each) | 1 dev | 1 dev | where developers privately test their in-progress work (possible alternative to laptop/wkstn) | comprehensive service virtualization |
| CI build nodes | many | microcosm | 0.01x | 1000’s a day | CI | CI | per-commit builds on short-lived feature branches (pre-integration to trunk/master), as well as post integration to trunk/master | comprehensive service virtualization |
Inching towards 100/1 - when starting at 1/100
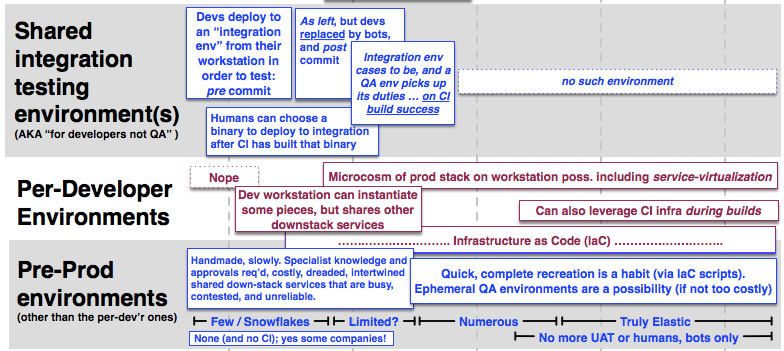
The lack of available environments is one the stifling factors for teams at the low cadences. While the goal is to CD into production (the same as famous companies do), the reality is that teams have to initially have more environments (by some definition) as they turn the cadence dial up. Then at a certain cadence, teams start to have fewer shared environments, and more microcosm environments. Ultimately teams have no shared pre-prod environments at all for the highest release cadences - even UAT is meaningless if you fire-hose into production.
Yup, More environment (types) before fewer, as you dial up release cadence
Teams between one release every fifty days and one a day, need release branches too, and possibly environments tied to those branches. That could be UAT re-designated on some fixed cycle, or it could mean additional environments. If the team is practicing concurrent development of consecutive releases, it could mean that there is another multiplier effect on QA and UAT.
Along the way the definition of ‘environment’ increasingly becomes unlike production:
- some services become virtualized so that “shared nothing” can be achieved (tests not failing because of entanglement)
- test automation increases in use, and is made to run faster and faster until it is performing at a rate that is an order faster than humans could achieve in the production app
- the build and test calculation gets smarter and finds ways to complete work more quickly. In part by safely running fewer tests.
Kill Integration (env)
The first target to kill off is the shared “integration” environment. That may sound counter-intuitive, but as devs are queuing for it, and at anytime it may contain binaries compiled from uncommitted code, it is definitely part of the problem. The goal here is to have comprehensive integration and functional tests performed on a private per-developer microcosm env (the developer’s own laptop/workstation), or a private per-developer VM if the RAM cost cannot be reduced to that to fit a laptop or workstation that’s concurrently running an IDE, email etc. When the developer commits and pushes their short-lived feature branch (SLFB) the CI daemon wakes up and repeats the build that the developer should have done before commit/push - that is using microcosm environments. If that CI build passes, and the code review is good, and the work is merged (Pull-Request style) into the master/trunk then the CI daemon wakes up once more and kicks off a build that tests everything one more time. That one has a 99.9% chance of passing, given the previous pass on the SLFB. Only after that does a deployment into QA happen, and QA is now a place for exploratory testing and not for formal or automated activities.
| Env Name | # | Type | $ | Deploy Freq. | Deploy-ers | Users | Purpose | Compromises |
|---|---|---|---|---|---|---|---|---|
| “Integration” | 0 | |||||||
| CI build nodes | dozens | a few VMs | 0.25x | 100’s a day | CI | CI | builds of batches of commits build by CI | some shared downstack services |
| “QA” | 1-4 | multi-machine | 1.3x | many tens of times a day | CI | QAs, users | Where QAs occasionally manually test code | shared downstack services |
| etc… |
^ your team transitions though this (and similar) when going from one release every hundred days to one release a day (and beyond)
All hail integration (activity)
Chatting with Martin for the TIA article, he highlighted the correct name for the merge of commit(s)s from a SLFB into trunk/master after code review and a build daemon have approved all, is “integrate”. That’s right a build bot said it was ready to integration, some humans did too after looking at the code, and any number of other bots weighed in on style/lint and other criteria. While merge is the VCS activity that does it, “integrate” is the software development lifecycle workflow activity for that moment. For teams with one commit every few minutes, humans can click a button in a UI to perform that. For teams with one commit every 15 seconds, then maybe a bot has to sequence a bunch of those as it’s too involved (refer the push/pull bottleneck).
A recap: Integration tests are run by devs before they commit, and bu CI bots after they commit, but before making a binary that would deploy to a shared environment. Integration of the commits into the trunk/master is the penultimate test work is complete. There’s only on more CI build to do on trunk/master to ensure there’s no weird timing-of-commit problems from two developer’s somehow quantum entangled work.
Facebook’s branches and environments
In 2013 I wrote about Facebook’s Trunk-Based Development: Facebook’s Trunk-Based Development (take 2). They were doing two releases each weekday for the main website experience, and organizing every on a military basis in order to achieve that. A month ago (August 2017) Chuck Rossi wrote about ratcheting up that achievement to now do three releases each weekday. I think that is probably the max release cadence that they will be able to hit with release branches at their scale.
They have a CI infrastructure that rivals Google’s, and SLAs that mean that CI is finished (to ‘pass’ or ‘fail’) within 10 minutes of the commit entering code review.
Their next move, I think, is to go to Continuous Deployment. Yup, to fire-hose all the way into production. At that point staff will stop dogfood-ing facebook.com, and place the final amount of trust in the QA automation activities. They also may break up facebook.com into many smaller things (quicker to build) that firehose into production from different builds, but are stitched into the identical experience in a style I’ve written about before - cookie cutter scaling. No, that’s not microservices, it’s a thing facilitated by a monorepo, TBD, and a directed graph build systems like Buck or Bazel. They’ll also need to jump to “fix forward” (when they encounter a bug in prod) from the canary design they’re doing now