Paul Hammant's Blog: An Aspect of DevOps Improvements: The Reduction of Cycle Times
An unconventional visualization of cycle times:
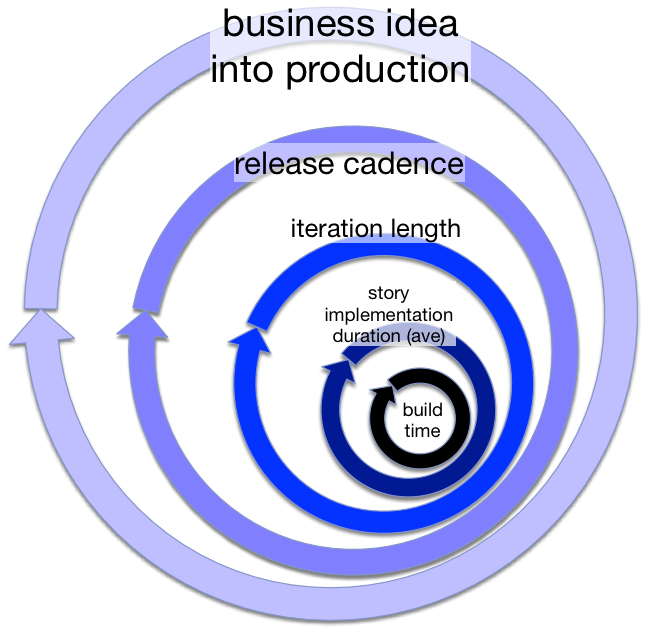
The idea is that you should try to reduce all of these so that s/w development can reach a Continuous Delivery and Continuous Deployment nirvana. You can indeed eliminate some of the cycles entirely, but only by inching towards them before being brave and eliminating one altogether. Iteration length might be one to eliminate if every iteration is released. Pretty close to the completion of this improvement agenda, you’ll eliminate the release cadence related cycle because you’ve reached CD. Before that though, you’ll have increased your release cadence (reduced the release related cycle time) one week or month at a time.
These cycle times are like russian dolls though: there is one inside the other, and the larger ones can’t fit inside the smaller ones. Thus there are constraints. Your effective build time, for one, governs how long short the next one (story development duration / story size) can be. Thus aim at reducing them all - and there’s no specific order to that - just a little bit here and a little bit there as cost effective improvements can be made (and where needed next as bottlenecks move around in a system).
Oh yes, and I may have missed a cycle time or two, in the diagram.
A typical improvement
(updates on July 5th & 6th, 2017)
This one is straight out of the AOL project that Jez Humble and Dave Farley were on in 2006. That was the project that gave them the experience to write the best seller Continuous Delivery.
They took a chunk out of the formal (and labor intensive) certification of a release, and replaced it with something that was part of the build, but far quicker:
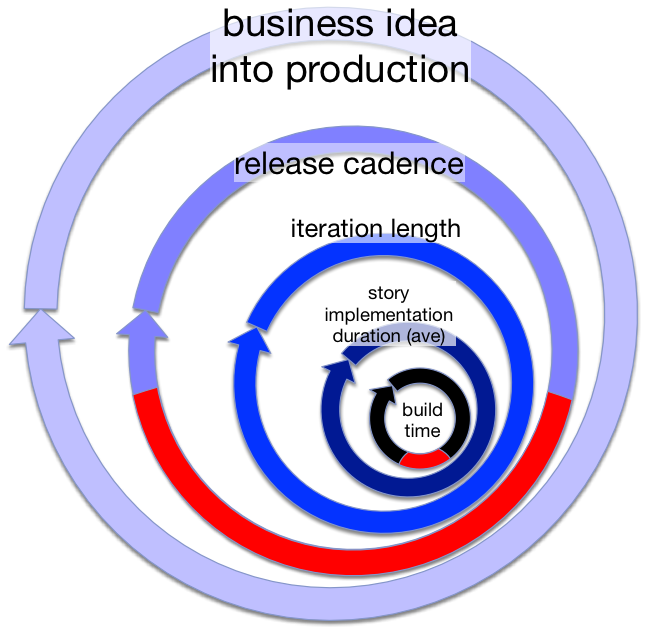
Sure, there are other ways to depict certification or sign-off, but you get the point, hopefully.
And if we think about the shortening of release certification, allowing for the release cadence to go up (time between releases to go down), then that becomes something that is not a multiple of iteration length. Therefore we in this hypothetical team (like many teams on that path to CD), make iteration and release cadence the same thing, with the more business significant of the two holding the name for that cycle:
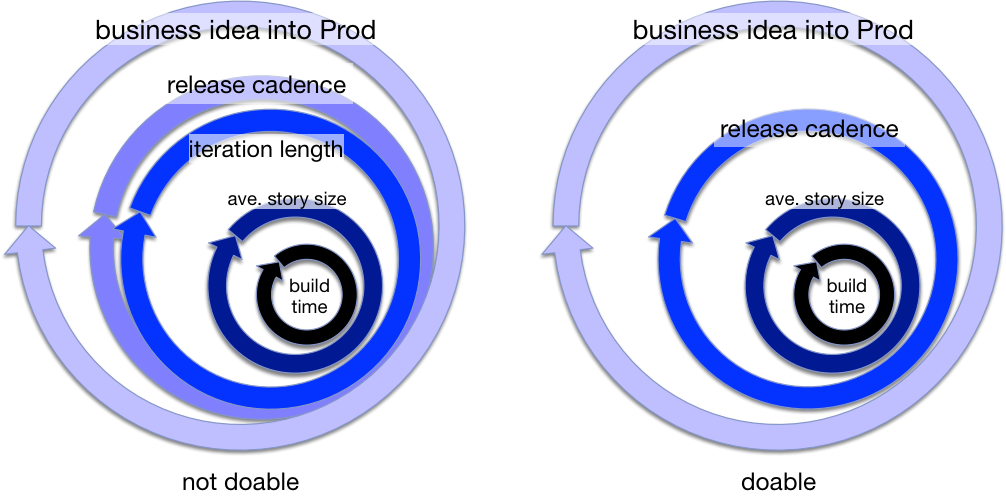
^ cycle times have reduced
The progression should be clearer there. As a team ratchets towards CD the cycle times get smaller.
The jump to CD
At a certain point there may be several deployments to prod inside of one build time. That is merely an observation that many developers are working concurrently yet independently on features that are eminently go-live-able once completed. Once completed is really as soon as it’s committed/pushed, verified by CI, and integrated into trunk/master, of course. The CD pipeline is going to push tens of features live a day, while the build time (etc) may end up being longer than the interval between releases. That dev team super achieved on test automation, of course. And the DevOps team has super achieved on build parallelization, allowing a perception of:
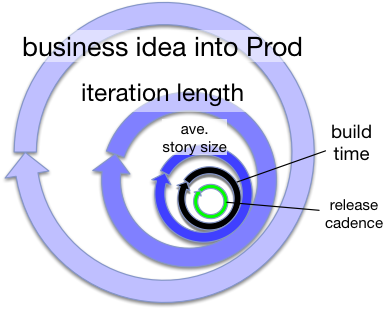
^ release cadence has jumped to a new place that mare than a ratcheting improvement (read on).
The green hoop is solely done by bots. No human participates in that cycle any more, so no human is delayed waiting for an individual deployment. Indeed, through that parallelization several commits may have builds that are at different stages of completion concurrently. Each will slide in to prod as is completes. All the other cycle times are ones that impede human throughput. Story size can’t ordinarily be shorter than the build times, because humans oversee both. If humans are taken out the execution of the final deployment step, that cadence can appear higher (interval between releases shorter). It is a perception trick though, even if it is safe to bet on.
As it happens, teams jump to Continuous Delivery (fire-hose into QA/UAT) first for some a period of time in order to experience the changes required to support that, before a second jump to Continuous Deployment (fire-hose into prod). Some teams - those who’s business hold them to sign-offs and related audits, will stick with CD into UAT, and only ever be weekly (or so) for go-live pushes.
That cycle time difference between into-QA, into-UAT and into-prod is not the exclusive preserve of the smallest-cycle CD teams, though. Even teams with larger cycle times may have had a different approach for their QA and/or UAT deployments, than for production. Indeed more than a single QA or UAT environment for a single prod environment, allows for more creative views of a team’s cycle times. And there are plenty of companies with that mismatch between QA/UAT and prod.
Speedy Builds
(update on July 8th)
Say you’ve done as much traditional mocking around component seams as you can in order to speed up the unit–test step the build pipeline. You have also used service virtualization (wire mocking) to speed up the integration tests (Mountebank is my favorite tech for that). You have parallelized what you can, and even leased browsers from a close-by cloud to chomp through Selenium tests for isolated UI components much faster than humans can work. The build is objectively fast for developers on their workstations in their regular development cycle (pre-integrate). The build is also faster from the point of view of the CI infrastructure. CI always had the advantage of being able run builds in parallel, and not have to wait for build #12345 to complete before starting build #12346, of course.
What next though?
Omnipresent compilers
One aspect of Google’s Blaze build technology is that it is able to acquire compiled code from team mates in a build cycle. At least where the team mate had compiled the same source inputs recently. That was an LRU cache. When I saw it, the implementation was Memcached, but I’m sure Redis would suffice these days. Buck (Facebook’s copy of Blaze), has such an implementation too with its HTTP Cache. This allows the shortening of the two compilation steps in a build - prod code and test code.
Test Impact Analysis
Provably run the minimum of tests impacted by the prod sources that have been changed since you (a developer) started work on a feature or a bug. This leverages a map between tests and the prod sources they would exercise.
Microsoft has this working well with TFS and Visual Studio, but I have a relatively cheap tricks for teams outside that ecosystem, that uses ordinary coverage tools to build the map. You may be able to skip 99% of your tests in a test run, for some changes, and still be highly confident that the commit (or commits) are good.
- Reducing Test Times by Only Running Impacted Tests - for Maven & Java
- Reducing Test Times by Only Running Impacted Tests - Python Edition
More in another blog posting.