Paul Hammant's Blog: Reducing Test Times by Only Running Impacted Tests - for Maven & Java
This article follows on from my Omnipresent, Infallible, Omnipotent and Instantaneous Build Technologies one a couple of day ago. Specifically the last section: “Minimalist test execution, via hacks”, that addressed test times being very lengthy.
I’ve made a proof of concept of that for Maven. The tests impacted by a change (a pending change specifically) can now be quickly determined and fed into the test runner to massively reduce test times. Massively reduced, this is, if you’ve managed to engineer hours of Selenium tests.
Proof of concept
I forked a Github project that Petri Kainulainen had made to discuss coverage for a Maven projects.
Clone my fork, but cd into the “code-coverage-jacoco” directory.
Running testimpact.sh there - it will rebuild a map of what tests cover what production-classes (sources). I’ve checked in the previous results from running this script, that’s what a team would do. It runs Maven against one test at a time, to calculate coverage then store that per test. Actually for Petri’s example, I’m only focussing on the integration tests (run by the “failsafe” plugin) rather than the unit tests (run by the “surefire” plugin). Even though Petri’s example project is not launching Selenium (or equivalent slow test), the integration test phase is where you would run that for a canonical Maven project.
The testimpact.sh script uses python and ack (you’ll have to install those if you want to run this). I tried to use sqlite3’s CSV ingesting, but it was impossibly opaque, even with using StackOverflow’s best Questions/Answers, so I flipped to Python. Petri’s example uses JaCoCo for coverage, which spits out a handy CSV report (as well as HTML).
There are some text files in src/integration-test/meta/ccexample that show the sources covered by each test. Yes, they are checked in. Those files end in .java but are actually plain text (sorry):
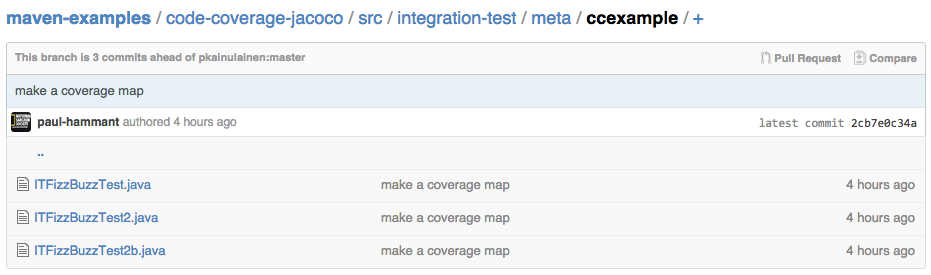
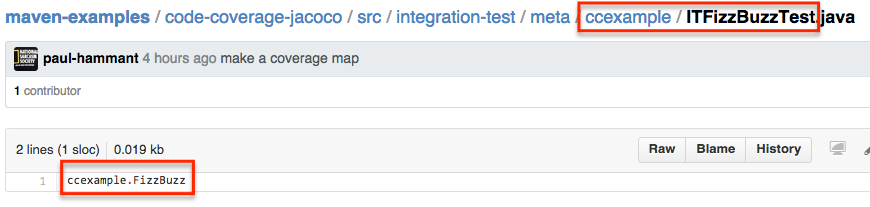
There’s another file src/integration-test/impact-map.txt that contains a list of production sources and the tests that would exercise them. Actually its a map of sources vs tests:
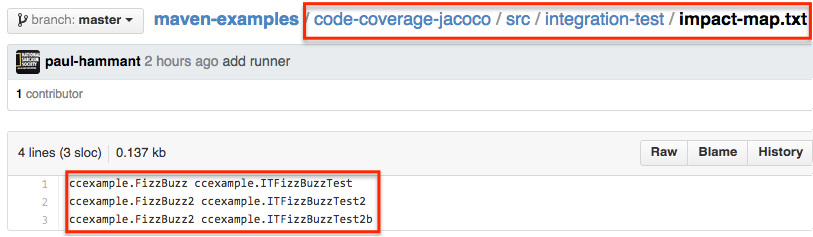
Experimenting with what I’ve done
Change one of the two production classes in src/main/java/ccexample. Yes they are clones of each other - that’s just something I did after forking to increase the class count at the start. Don’t commit that pending change, just leave it there showing up as modified in git status.
Run python tests.py and watch it run one or two tests in the same invocation.
Now undo that change, and change the other source file, and run python tests.py again.
Different tests ran, right?
Undo that change, and do python tests.py once more.
No tests ran, right? That would be the same for changed sources/classes that had no tests exercising them (covering them under test invocation) at all.
Of course these few tests are really quick, but they could have been three subset from hundreds or thousands of tests with an elapsed time of many hours.
-
Turning the idea into a solution
- It is also worth noting that scripts as I have them are not robust or optimized.
- There’s more source-control systems than just Git, of course.
- The script needs to be able to work for a commit too, not just a pending commit.
- The storage format for impact-map.txt will not scale, and you might want to excise certain categories of POJO if every test exercises them.
- To be correct in Maven-land, this should be a bunch of plugins that fit the Maven style. One plugin would be invoked from Jenkins and would probably run constantly if corresponding test times are up in the hours. That Jenkins job should check in changes to the meta-files as it sees changes. This is benign, and useful to team members who may want the shorter build.
Would you check the impact map into source-control?
It seems to me that the map data is related to the other source files. Perhaps if you took a historical view to things, the impact maps change with the source code at the same time. If you were bug-fixing something from the past (checking out a prior revision), you might be happy that the impact map also goes back in time.
Of course there’s nothing here that couldn’t be stored in a key/value store, including the changing map over time. Or a service that could answer the question “what tests should I run if these source files are changed?” Except perhaps that uncommitted work (on your own workstation) isn’t going to be present in that store until after a commit, and the impact map data us updated to that into account.
Taking the idea even further
- I’ve suggested that Selenium is the technology that would greatly lengthen test times. There are many other test technologies that are one, two or three orders slower than perfect unit tests. This idea is applicable to much more than just Selenium - the only requirement is to be able to measure coverage while individual tests are running.
- What I have done could also be extended to the “surefire” phase - almost identical to what I’ve done already - an opportunity for reuse of course.
- CI daemons like Jenkins could benefit from the same impact-driven test time reduction. At least the per-commit jobs that we do for the Continuous Delivery era of enterprise development.
- This idea could be extended to the test-method level. That would be harder still, but achievable in the same way. It comes with arguably negligible gains, though. You’d code it all, and work out that 5% wasn’t worth it (versus other ways of speeding up tests).
- We’d need Intellij and Eclipse plugins for this.
- The script needs to be able to work for range of commits as many teams batch them in in Jenkins-land.
I wonder what is out there that already does this sort of thing already.
Followups (Jan 13, 17, 2015)
Markus Kohler notes:
This is a great idea and I guess similar to what Google does (there was blog post about it, can’t find it ATM).
But I think as it is it would not be completely correct.
The reason is that as far as I can see, you just run the tests that use the modified class files. That is not enough, because in Java changing one source code file might result in other files needed to be recompiled.
Gradle’s Java plugin computes that set of files for example for incremental compilation.
As an example if a final static String is changed and that String is used in other classes, these classes has to be recompiled because the Java compiler inlines these kind of strings. Any Test that uses these classes would have to be re-run.
He’s quite right there’s room for some edge case mistakes. To overcome those, you would need to check for changes that would lead to final static fields being inlined into other classes. Maybe a list of source files that, if changed, would cause all tests to be re-run (after a suitable warning).