Paul Hammant's Blog: Trunk based development: when to branch for release
It does not matter if you’re using Git, Mercurial, Subversion, Perforce or TFS. This definition below is the same for each.
Not branching for release
Here’s maven doing an actual release for me in a Git repo:
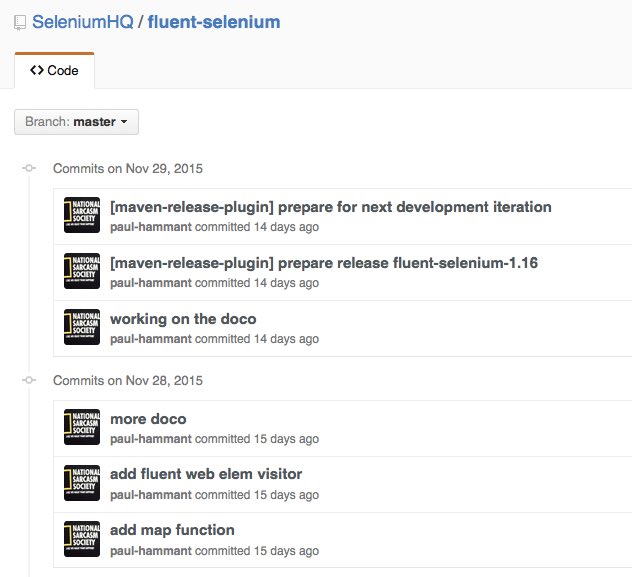
The evidence is two commits - one for v1.16 of FluentSelenium, and the following one is for 1.16.1-SNAPSHOT (SNAPSHOT being Maven’s code phrase for work in progress). Maven went and pushed the 1.16 jars off to globally available repos.
Anyway, it was me not making a branch for a release. Sure, I needed other committers to not commit while I was doing a release. For other languages and other build technologies, or Java teams not using Maven’s release-plugin it might not do commits to signify “release is currently happening”. In that unpolluted commit-history eventuality, I’d be able to do the release from a specific commit (or tag), and not require devs to stay out of the trunk for a few minutes.
Teams that are adept at Continuous Delivery (CD) are doing it this way - releasing straight from the trunk. Maybe not every commit, but ones that have at least passed every automated test, in a multi-stage Continuous Integration (CI) pipeline.
Bugs in the release?
If you’re a hard-core CD team, you’re probably going to do another release from trunk to fix that bug.
If your cadence into production isn’t a couple of time a day, you might prefer fix the bug on the trunk, and cherry pick the bug fix to the applicable release branch. Of course you didn’t have that, so you belatedly create the release branch from the right commit hash/num specifically for this bug fix (and others that may follow), then do the cherry pick. Teams that are doing it this way are often going to want to manually test the bug has been remediated based on a build from that branch. If you’ve gone to the effort to make a branch, you clone the trunk’s Continuous Integration pipeline into one that guards this branch.
Branching for release
Note: I’ve hacked up a clipped image to show something that didn’t actually happen. The branch would be made from a specific commit (or tag, or just HEAD) and named for that release, in some days or hours leading up to a release:
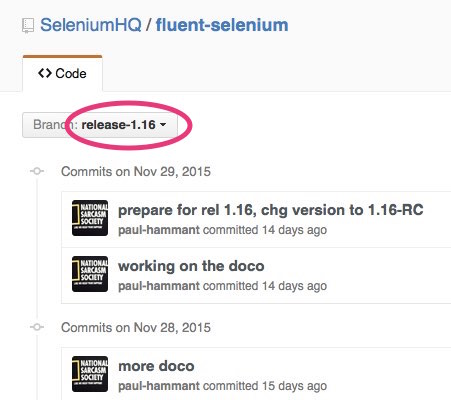
The enterprise in question intends to harden the release on this branch. The first and maybe only true commit on the branch is one that updates version numbers to signify the intent - in this case a “release candidate” for the release. Other enterprises could go straight to “1.16”. You also always clone the trunk’s CI pipeline into one that guards this branch.
No commits were made on the trunk (Git’s master in my case here). Thus developers did not have to slow down at all in the rate at which they were committing to the branch. Especially not the dreaded code-freeze popularized in other branching models. I’m talking about you, ClearCase!
Merging bug fixes back from the release branches to the trunk?
Not if you can do it on trunk first and cherry pick to the release branch instead. No risk of regression. Note regression means “things go backwards”, “regression testing” means a mechanism to guard that things did not go backwards.
When to delete release branches?
When you’re safely in the next release cycle - meaning you’ve done a deploy to prod and it’s going to stick. And yes, you should delete release branches after they’ve fallen into disuse. They’re still there in history but a merge-meister might not cherry-pick into the wrong branch if there’s only a couple of release branches in play at a time. The CD-style firehose into production from trunk, should be your goal though. i.e. no branches.
Why cherry pick?
Well because you only want the release branch (if you created it) to differ from how it was created by the smallest possible amount.
More reading
I’ve been writing about this stuff for more than eight years of course, and practicing it for more than 17.
Here’s an article with a few charts of practices correlated to trunk based development: trunk supporting practices
There’s also my whole trunk based development category