Paul Hammant's Blog: Trunk supporting practices
 |
Note: Artwork and concepts from this blog entry features in the best selling software development book Lean Enterprise: How High Performance Organizations Innovate at Scale (2015) by former colleagues Jez Humble, Joanne Molesky, and Barry O'Reilly. |
I’ve been doodling a particular chart for few years, and put a version online with the article Facebook TBD take 2. Forrester were highly inspired for their More Engineering, Less Dogma: The Path Toward Continuous Delivery Of Business Value  report aimed at executives. I updated the graphic to cover code reviews too with Non-Continuous Reviews, but it is time for a larger overhaul.
report aimed at executives. I updated the graphic to cover code reviews too with Non-Continuous Reviews, but it is time for a larger overhaul.
Now in three smaller diagrams (slide sized), I have more activities, practices, strategies, and aspects of software development that typically have a variation that’s correlated with trunk based development and release release cadence. These things, I feel, suggest that corporate IT departments should think about trunk based development as the foundation of their software delivery. Clearly there is a Continuous Delivery (CD) aspect too, but I’m most interested at the moment in the “Trunk” focus of the message in this article.
Branching, code sharing, and non-atomic changes
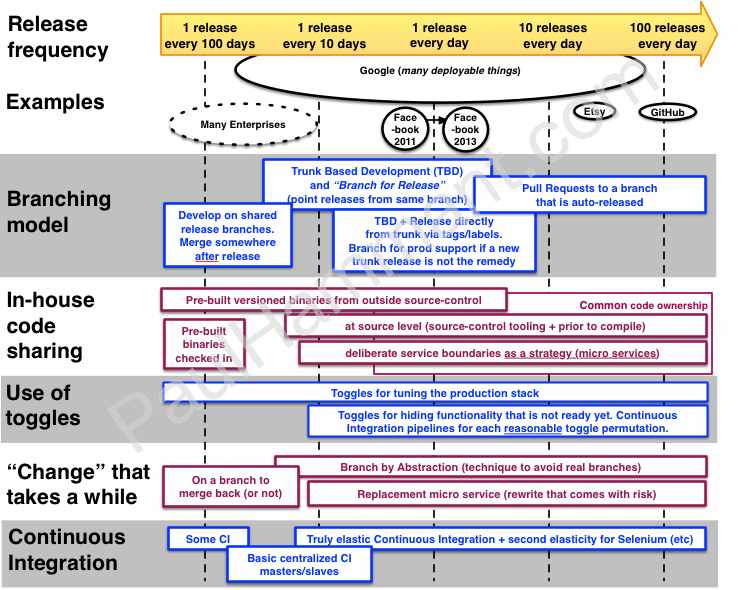
I’ve written about trunk based development quite a few times. Refer to my article What is Trunk-Based Development?, so I won’t cover what it is and what it is not in this article.
For an example of “Changes that take a while” think of a change to something non-functional that may require several person-weeks to complete. Like a change of Persistence technologies (e.g. MyBatis to Hibernate in Java-land, or NHibernate to Entity Framework 6 for .Net people). In this scenario you could have three releases to push out after you start this exercise, but before you’ve finished it. Finished includes “thoroughly tested” of course. All of these, I maintain, are supportive of concurrent development of consecutive releases (and hedging on the order of those).
Google being the example, common code ownership is key to one path to high release cadence. Code is shared at the source level, and subject to a speedy code review developers can craft a wide ranging (hopefully atomic) change list or set and expect that to be consumed. That is even true for components that are not ordinarily the preserve of the application team in question.
QA, non-live environments, and dev workstations
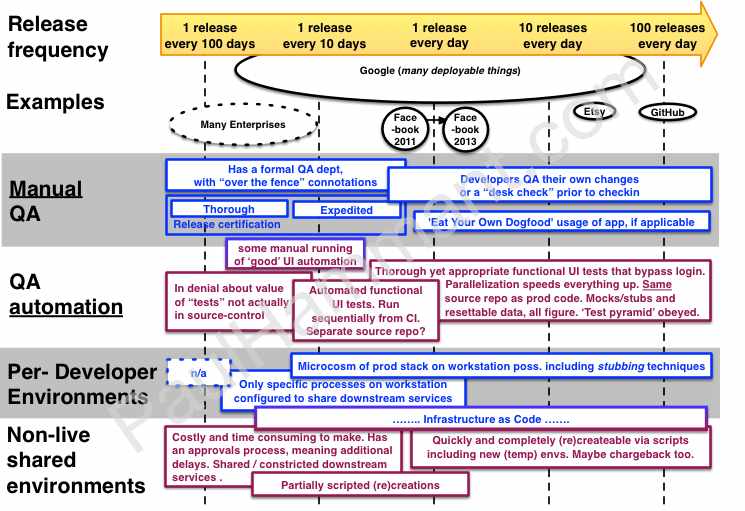
In corporate IT departments there is sometimes an unrealistically optimistic view of the QA group’s assets. I’m showing that in the QA automation line, to the left. Both per-developer environments, and non-live shared environments should utilize “Infrastructure as Code”. That is an industry trend that is correlated with increasing release cadence. As part of that there should be scripting commonalities between the shared non-live environments, and the microcosm that would be a developer’s personal deployment on their workstation. That last, ideally, is one process maybe utilizing IPC sockets and programable stubs (as far as possible). Infrastructure as Code has an impact on trunk based development in that such scripts are ideally NOT in the same repository as the application code. Not in the trunk, in other words. I’ve written before on that.
Others…
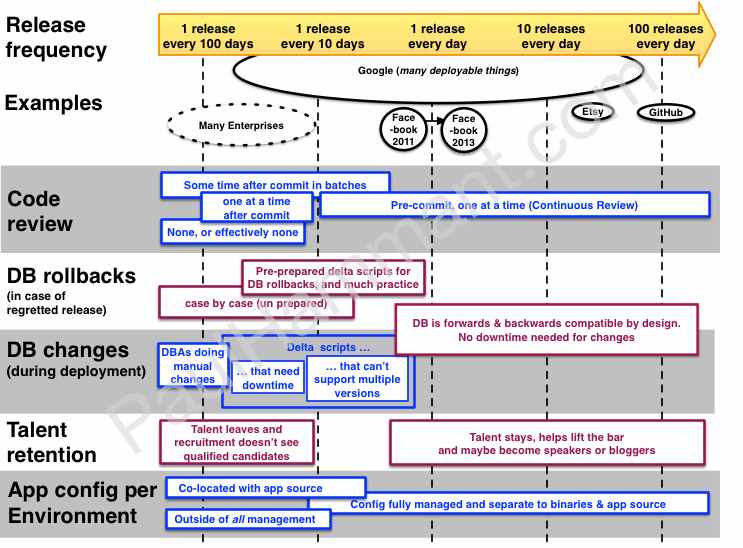
I wrote about Continuous Review before on the subject of code review as a core developer team activity (Non-Continuous Reviews is a follow up). Continuous Review is highly correlated with Trunk-Based Development at scale (Google and Facebook being the prime examples).
Talent: Everyone wants to be a destination employer right? Ignoring salary, free-food and fancy chairs, technology excellence is one aspect that helps you retain and attract talent. In other words your reputation as a brain-trust and great project work attracts talent.
Database table-shape upgrades in the event of a release (and downgrades as a consequence of a regretted release), are something that changes with an aherance to a trunk philosophy. It’s also more of a per-release thing than regular incremental application development. It takes a ton of choreography. Perhaps reading Pramod Sadalage’s Refactoring Databases: Evolutionary Database Design will give deeper insights than this blog entry.
Environment config, isn’t the same as “infrastructure as code”. This is the stuff that’s potentially live-tunable in an application stack that subsumes feature toggles, but goes further - application specific things not limited to rectangles of web-pages appearing or disappearing. It is managed in its own place (Zookeeper and its underlying data files being a common choice) on the right hand side of the diagram, but I personally believe that it is best under source-control. That would not be the same repo as the application source. Ideally that would be one branch per environment, giving an additional diffing benefit. I’ve met one client that had such config under source-control, and could hypothetically do round-trip editing of that. They used branching as the way of promoting sets of towards live (and bringing live changes back to staging, UAT, etc). Again, to reinforce that - not on the trunk as I’m trying to otherwise promote. I’ve called that “Configuration as code” and although I think it should be the technique for high-cadence teams to the right, it isn;t right now.
Missing from the diagrams
- Refactoring as a practice to guard against technical debt. I think that technical debt can happen for any team on the spectrum I’m representing for 1/100 to 100/1 regardless of source-control usage.
- A visualization of “Production immune systems” versus “snowflake” on a continuity for Operations/Infrastructure.
- Automated production release monitoring and noting differences in the behaviors of the production stack, which is a real thing for adept organizations, but not correlated with trunk based development.
- Incremental rollout, as I’m not sure if all organizations towards the right do it, or need to.
- Whether an org has a “PMO” sequencing projects and delivery? Is that a line on its own? Perhaps yes, one called, “Biz/IT Prioritization”, and it is correlated to trunk etc ??
For Continuous Deliver per se, it’s Jez’s Continuous Delivery book that goes furthest in explaining to steps needed to transform from enterprise behemoth to lean machine, so go read it.
If you’d like help getting your organization to Continuous Delivery (via Trunk-Based Development or not), contact me.
Thanks to Jez Humble, Rolf Russell, Pramod Sadalage, John Spens, and Graham Brooks for contributions.