Paul Hammant's Blog: Omnipresent, Infallible, Omnipotent and Instantaneous Build Technologies
Claim: In 2014, build technologies should be omnipresent, infallible, omnipotent and instantaneous.
Context: This article is about enterprise development teams who collectively issue many hundreds of builds a day, as they work on features or bugs. The third-party stuff they pull in (Tomcat, Apache. MySql) can use whatever build technologies they like - this isn’t about those. It is about multi-module, multi-application source-code organized in “one big trunk” with different teams focussed on different things from different or overlapping sets or directories of that source tree. It is about making the shortest build times from potentially very large build trees.
A Hypothetical two-app example
Say Myapp1 and Myapp2 are maintained by different project teams, and go into production on different release cadences. They both depend on the same libraries: log4j (third party), and “common” (something made in-house). Both are in the same branch (trunk) of the same repo.
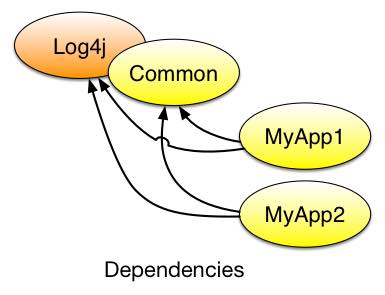
What my headline claim means
Running a second build straight after a first, should be as close to instantaneous if nothing else has changed between the two builds.
With respect to the well-known test-pyramid (a Martin Fowler blog entry about a Mike Cohn publication), the thinking is tests are one of the following:
- unit (each test is < 1ms)
- integration/service (each is < 1 second)
- acceptance/functional (Selenium etc, and perhaps greater than 1 second each)
Google wrote about this too with test sizes in 2010, and they had this baked into their build-infrastructure from at least 2007 (predating the Mike Cohn publication).
In modern CD-centric builds, as developers (or CI daemons), we would regularly do one of these by choice:
- compile only builds
- compile followed by tests that don’t require application/service deployment
- compile followed by tests including functional/acceptance tests that require application/service deployment
It is possible to do full Selenium (acceptance/functional) tests on components outside of the larger application deployment, but most companies don’t do that yet.
For our contrived two-app example, we should analyze a graph of additional triggers for stages of a build:
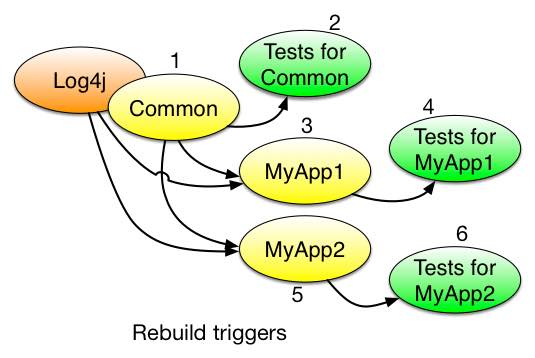
Additional to the source for that node changing, of course.
As it happens, 3 and 5 could or should happen in parallel. If that can happen, then 4 & 6 could also potentially be in parallel as a consequence.
Skipping compile when it is not needed
If you just did a build, and nothing else has changed, then you don’t need to recompile object code. In order to do that you need to track what source code made what object code. In order to do that, you need to match timestamps between the former that created the latter. Alternatively, given that is naive, it would be smarter to rely on hash-style functions of source and other inputs that created the object code. In this instance it might be better to work at the directory level rather than the source-file level, though there are some speed tradeoffs there. You could make a case that the per-source-file and timestamp tracking version isn’t infallible (at least for some languages).
Compile artifacts being idempotent is key here. The infallible aspect here means that compile should not be skipped if compile would fail - you have to be 100% sure that it would not fail, and the previously build binary is what would have been produced by it.
Skipping tests when they are not needed
Skipping tests is a more difficult decision to make. A naive implementation could skip tests if the prod-source, test-source and all relevant inputs are unchanged since the last run. Oh AND the last run yielded 100% passing tests. Dependencies (including transitive ones) might change that though. Whether binary or source (from outside the module in question), if they have changed then the fact that the previous compile/build had 100% passing tests is irrelevant. The infallible aspect here means that the build technology should not skip tests (indicating they should all pass), when some would fail.
Further complicating matters is that tests can be subsetted. You may have run only unit tests in the previous run (skipping integration/service and acceptance/functional). If you’re not similarly running the same suite in this run, the build system should know how to optimize which tests have to be run or can/should be skipped in the following build.
Leveraging co-workers recent builds.
Say you and “Jimmy” both came back from vacation, but Jimmy is in work 30 minutes ahead of you. Everything he does, you’re going to do too, but 30 mins later. He catches up in source control (svn up or git pull). He issues a build, which because he’s been away for a while, takes 15 mins - a lot is new the last build he did before his vacation.
When you come in, you do the same catch-up in source control, but your build takes 2 mins. Why? Your build should be able to pull compiled artifacts from Jimmy’s system (assuming the same compiler version). Sure he might have cleared his build artifacts already, but the build technology should have pushed them into a shared cache for nearby people or daemons to leverage. Obviously may be some LRU aspects to the cache, which is why I made this very contrived case in terms of timings. As it happens Jimmy’s worst case scenario (15 mins) was likely not realized either if there were more people in the team that have been building HEAD recently.
CI has needs too.
Per build pipeline, CI slaves nodes will need to leverage each others build artifacts and test results. In between assigned builds, they should make an effort to catch up to the latest known passing build’s revision AND the artifacts and test results (all passing obviously).
Buck by Facebookers (and ex-Googlers)
Buck is an attempt to target a multi-language source reality for larger companies, and reduce build times to the absolute minimum. Simon Stewart (Mr WebDriver) is one of the Facebook techies leading the effort. He’s ex-Google and ex-ThoughtWorks too. He remembers Google’s fabled Blaze build system very well, having previously been Googler. He also made CrazyFun for the Selenium2 build in its image (while a Googler). I blogged about Buck when it was launched. The same day Thomas Broyer went deeper.
Ahead of the actual compile and tests phases, a controlling process walks a graph of source to check:
- whether all dependent modules are available in the checkout
- whether there are any circular dependencies in the above
- what production source sets need rebuilding
- what test source sets need rebuilding
- whether there is previously built object code available in the shared cache
- whether there is previous relevant test results in the shared cache
Simon tells me that cache eviction need not be LRU, and that advanced systems might compute the cost of the artifact and keep the most expensive. He also notes that each target is treated as a pure function. Specifically if the inputs have not changed, the output are expected to be identical.
Maven: recent enhancements
Maven is the Java ecosystem’s dominant build system. It has been for ten years or more. Jason van Zyl is its creator, and though it is now ordinarily hosted at Apache, it’s plugin architecture is very open, and it is easy to contribute modified or alternate plugins from afar. Maven used to be purely iterative in it’s progression through trees of modules to build.
Jason’s new boutique consultancy and services company around Maven is takari.io. Of many skills Jason has, tenacity is the one you should note. Maven is intermittently criticized over the years, but it keeps pushing forward - Jason keeps pushing it - never underestimate his willingness to keep pushing forwards.
Maven Smart builder is the newest initiative that Jason is front and center of, driven by his client’s needs. It skips stages if it can because of idempotent build artifacts. The newer Maven is much more effectively multi-threaded now too. It is largely a migration path for existing Maven teams, and pushed into the “repeatable build” territory. With this initiative comes a focussed incremental build API, the “smart builder” piece, and perhaps even a new CI daemon that’s tuned to enterprise needs for Maven builds.
Differences between the Maven and Buck way.
Buck is attempting to be much more language neutral. Python (including test invocation and binary/library creation) is covered. Java too (Android and J2SE), as well as C and C++. No Ruby or DotNet yet, but contributions are welcome. Buck is also Unix only for now - no Windows capability yet - though the team wants to get there.
Maven is pitched at the Java ecosystem, which includes the Groovy, Clojure and Scala languages. That said, it also handles C++ projects. It also has first class support for pulling dependencies from ‘Maven Central’ and publishing released artifacts there too. Maven works on Windows, Linux and the Mac.
Buck has a daemon that’s deployed on your workstation - “buckd” - that watches for what’s happening with source files, and feeds into the build in order to correctly optimize things. A similar “mavend” is forthcoming.
Source layout
Consider Source Trees for a hypothetical example:
Maven’s source layout (pom.xml is its build file):
<root>
pom.xml
common/
pom.xml
src/
main/
java/
com/
mycompany/
common/
(*.java source as expected)
webapp/
(perhaps JavaScript is in here)
test/
java/
com/
mycompany/
common/
(*.java test source as expected)
myapp1/
pom.xml
src/
(*.java prod and test source as expected, at deeper packages)
myapp2/
pom.xml
src/
(*.java prod and test source as expected, at deeper packages)
Buck’s source layout (BUCK files indicate it’s build grammar):
<root>
BUCK
java/
src/
com/
mycompany/
common/
BUCK
(*.java source as expected)
myapp1/
BUCK
(*.java source as expected)
myapp2/
BUCK
(*.java source as expected)
test/
com/
mycompany/
common/
BUCK
(*.java test source as expected)
myapp1/
BUCK
(*.java test source as expected)
myapp2/
BUCK
(*.java test source as expected)
javascript/
(showing a hypothetical two-language situation)
third_party/
log4j.jar
SCM support for sparse checkouts
Subversion naturally allows you to checkout from a sub-directory if that makes sense to you. Git and Mercurial only allow checkouts from the root directory. Perforce makes you define a client-spec which could effectively hide the root node (meaning it is similar to Subversion).
Subversion allows you to do a “sparse checkout” from root in a non-recursive way, and the go on to specify a subset of the directories therein to further checkout (and track going forwards). Git also has “sparse checkout”, but the coupled clone is not sparse. Mercurial also has something coming in this design. Perforce, via the same client-spec, allows the directories at any place deeper than root to be included or excluded. Buck totally embraces that way of working, as did Blaze before it. That’s how you manage a large HEAD revision set for a “one big trunk” model down to just the bits you’re interested in.
Buck and the newer Maven will work with a partial checkout, but only if a critical module is not missing. A Developer chooses to checkout the common and myapp1 directories (but not myapp2) … the Buck and Maven will still build correct artifacts for that from root, and run tests for them. Only if that’s possible though, as I said, you couldn’t checkout myapp1 without common (for my contrived example).
Maven similarly allows subsetting. You can checkout from any of the subdirectories with a pom.xml in them, and build from there. In that case Maven will pull dependent artifacts from the maven repo it is configured to use. If the parent module suggests to recurse into myapp2, but it is not in the sparse checkout then the latest Maven will not fail with an error.
Third-party libraries
Maven’s natural inclination is to pull third party dependencies from a local Maven repo (which in turn might have come from “Central”). Before Maven, even the Java community was used to checking in binary dependencies. The Maven ecosystem is so dominant for Java build technologies that even the competing build technologies (Gradle etc) pull down deps from “Maven Central”. Maven naturally places them in a .m2/ folder in your home directory. An example is “test” dependency “junit-4.12.jar”. Note that it is in the repo with 4.12 in its file name, meaning some modules could depend on different versions. That last means lock-step upgrades are not necessary, and clashes have to be detected by Maven itself at build time, before they cause tricky-to-solve problems at run-time.
Buck, like Blaze before it, pulls dependencies relatively from the checked out directory. Classically, that’s a third_party/ directory in root. It is not wild-card included in build paths. Instead each dependency is listed in the BUCK build grammar as a dependency. With reference to the test dependency on junit - it would be in third_party/ without 4.12 in its file name, meaning no modules at all could depend on different versions. That last means lock-step upgrades is normal.
Hypothetically for Maven, you could pull dependencies relatively (that third_party/ directory) from the same checkout, but nobody does. I would like to see that explored more. Especially when Git solves its binary files problems.
Build Order
Both Maven and Buck will build modules in order. As they go, they work out which build to step into and when the pre-requisites facilitate that. If MyApp1 and MyApp2 were in the checkout, it would build common first, the MyApp1 and MyApp2 (possibly in parallel given the Takari enhancements).
Buck will chose to fast fail if dependencies are missing at the outset. Maven may fail part way through if dependencies are missing, because it is recursing methodically. Maven will fast fail if there’s a circular dependency amongst the actual modules themselves, though.
Maven also quickly builds a tiny parent module first - just as a reusable memo of the parent/child relationships and any data sharable at runtime that was common to all.
Maven isn’t quite omnipresent with respect to skipping test-execution yet, but it is coming Jason tells me.
Stages 4 and 6 (and 5 & 7) are parallelized by both Maven and Buck.
One big trunk.
We’re encountering lots of companies that have “many trunks” these days. Perhaps they are sipping from the SOA or MicroServices cool-aid, and have a lot of subversion repos - one for each service. They’re self-reporting that they are in fact doing Trunk-Based Development. That’s really never what we meant when we advocated Trunk based development - especially for enterprises. What we meant was “one big trunk”. One, not many. We might have to really focus on the “One big trunk” title going forward to differentiate.
Simon has written about this before. I’ve written a few too.
Minimalist test execution, via hacks
I’m not providing software here, just a what you need, recipe:
- In a CI build-job that’s perhaps always running against HEAD, run one test in isolation such that you can work out which source files were utilized during it’s execution. Write a “ProdSourceFileName” line to a file that ends in TestSourceFileName.sourcesUsed text file is close to the actual test source file. Maybe that’s a hidden file. Maybe that’s a hidden folder (preserve the paths in question too). Check that file in to the repo. Yes, the same repo. Yes, check it in. Yes, people will get it if they “svn up” (or equivalent).
- Take all of those files (perhaps daily) and flip the information and write a new text file (or JSON or XML). The lines in it would be “SourcePathAndFileName (space) TestFilePathAndName (carriage return). Check that in too - perhaps in the root - try to make sure that the file is sorted consistently (to aid diffs).
- Have a mode of operation for your test runner that uses the new meta file to reduce your whole test-base down to just the ones impacted by the modifications you are dealing with (via “svn status”, or equivalent).
It would be nice if that was impacted methods rather than impacted sources, but that’s much harder to collect. Note that code coverage is not the same for every language, nor is the relationship between source file and object-code.
Updates
Bazel
Blaze was open-sourced as Bazel, back in Sept 2015.