Paul Hammant's Blog: Non-Continuous Reviews
I’m contrasting the nature of code reviews for organizations in this article, by source-control branching model.
Chasing HEAD on trunk
A recap from a previous article on Continuous Review (mostly about Google, but also Facebook it turns out):
We’ve seen that Google and Facebook do a Continuous Review that’s tied to their Trunk-Based Development. Things get developed (including tests), submitted for code review (with auto verification), and on approval by more than one person get pushed into the trunk. If they are not approved, then the developer goes back into the IDE for more changes. Everything is current. It is also commit by commit (with focussed commit messages). Developers (using local branches) may squash a few commits together before bowing down before the code review gods, or they may not. Bringing your working copy up to date (p4 sync, git pull, svn up) might happen more than once in that cycle, but nobody fears that. You cross you fingers that there are no merge conflicts, and usually experience that there are none.
Etsy, Netflix, Github and others live a round a pull-request driven code review. The pull request triggers automated verification, and a review happens there. The commit languishes in pull-requests limbo until it get’s approved and consumed into the trunk (master). At that stage the place the commit was marshaled on (effectively a short-lived task-branch on a fork) is unimportant. It could be deleted. More likely is that the developer who was using that fork might keep it and start work on their next task there. Of course, given it’s DVCS they could be doing more than one thing in that fork, on different short-lived tasks branches.
There’s no code freeze for Continuous Review, if you couldn’t guess.
Lastly, I talked before about Testability and Cost of Change, and it is worth remembering that the sooner your find a mistake the cheaper it is to fix.
Code Reviews on a Mainline model
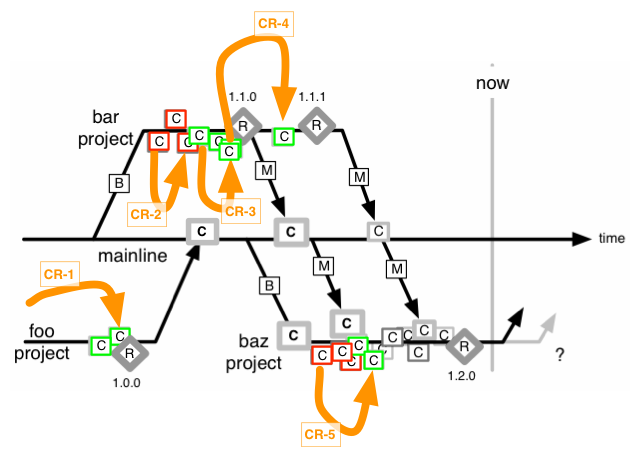
A reminder - the ClearCase Mainline model of yesteryear meant that releases were done from those long-lived multi-developer project branches, before the code was merged back to the Mainline.
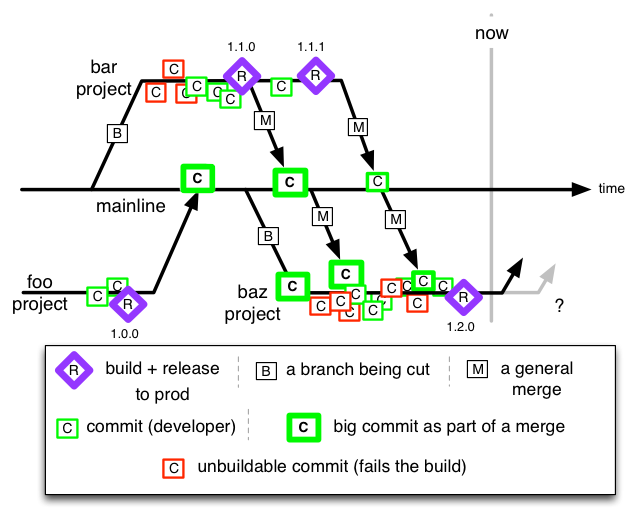
I’m going to outline two different style of code-review for mainline: both of which represent delay between error and detecting/remediating error. Don’t forget that cost of change curve article (linked above).
Big Code Review in Advance of a Release
One person review the entire thing
This could be your company’s policy. It could be because you couldn’t afford (it was claimed) to do Continuous Review. It could be because you forgot, and now because of some pressure (maybe compliance, regulators, CIO/funders, client’s contract) you’re doing a review in a oner. Of course that’s like a punch in the face for a single reviewer if the dev team was 30 people, and they toiled for four months to get to this moment. If you stick with that plan, the review is going to be a lip-service one, as nobody wants to wilt and die trudging though that. Yes, defects in various guises will creep in despite us assuring the bosses that it was a diligent review.
Dividing up the work
Of course you could make 5 of the developer divide up the work over a short period around ‘code freeze’. Most likely developers will get groups of files each. There’s new risks with that. And we’ll highlight one thing that Agile teams are historically good at, and waterfall teams not so much: Refactoring. We’ll talk of just one refactoring “pull method to super class” (yes yes, we normally prefer composition over inheritance). Say foo/framework/AbstractSiteAction.java had a subclass foo/zepher/checkout/CreditCardPurchaseAction.java and the latter had (in release 1.1.1) a method @verifyCardFields(Field[] flds, Validator[] validators)@ but a refactoring moved that to the parent class and renaming it to verifyFields.
We might have given everything in foo/zepher/ to Zak to review, and everything in foo/framework/ for Fannie to review. Zak looks at a wholly missing method, and wonders if it went to one of the super classes. Even if he had a diff in (say) Crucible for all of his files that he could scroll up and down in, he’d have to do a huge amount of scrolling. It could be that he does not have the entire diff within a single view. He’s now tempted to click on a few navigation aids to open up the parent class(es) speculatively to see if the method was moved faithfully. Crucible (and the others) are web-apps, and don’t have a sophisticated multi-tab interface that allows him to keep many sources open. He’s going to be cursed to navigate all the way back again, assuming he can remember. Of course in reality he slips towards a lip-service review again. He didn’t even try to make sense of the mashed together commit messages.
Fannie is equally confused too - she sees a new method in AbstractSiteAction.java and really doesn’t know much about it. Even split between a few people, the size of the mashed together diff is hurtful. That and distant (in terms of navigation) unit-tests and rambling concatenated commit messages make push this towards pointlessness.
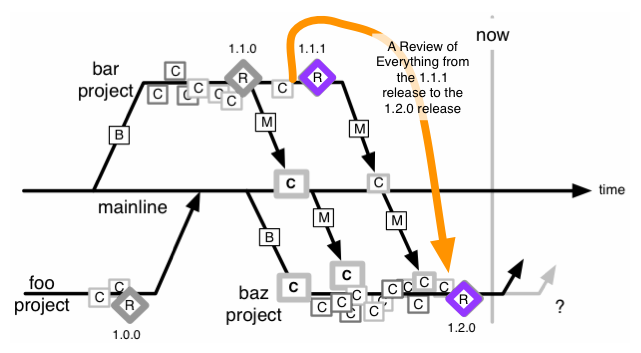
Periodic Review of a Batch of Commits
Now we’ve attempted to break this up into shorter reviews. Ones within a single project, that is. We still have some of the rollup confusion outlined above, but it should be assignable to one person for review. Care has to be taken to have a meaningful start and end commit. You’re also going to leave out the merges back to Mainline, as they are a tsunami of change that we’re not wanting in one review. Not only that, they are reviewing things a second time. Hopefully those merges didn’t change anything they were not supposed to. Shhh, don’t tell the auditors that we’re not reviewing those.
Conclusion.
Ten months ago looked at Facebook’s Trunk-based-Development, and made a diagram to chart industry players and regular enterprises on their practices versus their release cadence. Here’s an add-on for that diagram, contrasting Code Review on the same progression:
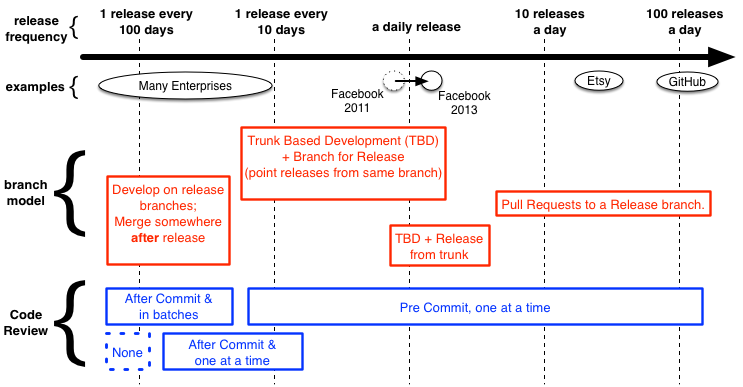
Note - I’m showing “none” as a strategy, but the adjective ‘inconsistent’ could also be shown, and many enterprises would recognize themselves in that.
Continuous Review in the style that Google, Facebook do, or the pull-request centric way of Etsy, Netflix, and Github (and many others) is the only efficient way to review code. They’re easy to count off (you can prove you didn’t miss one). They are quick, apply to stuff that is happening now, and the commit message has direct context for the hopefully manageable diff in question (Refactorings don’t add to the confusion). They are still cheap if you make more than one person review them. Remember that cost-of-change-curve stuff too, and lip-service factors that exacerbate that - we’d be avoiding that. Not doing Continuous Review is nuts in my opinion.
Clarification.
Via Disqus, Evan Jones asks:
Call me crazy, but it seems to me like the Google/Facebook style of review, and the Github/Etsy/Netflix model are the same. Care to elaborate why you say they are different? As far as I can tell from your description, the only difference is that Google/Facebook use local (unnamed?) branches, whereas with pull requests the branches are named and available from the server.
I agree that it sounds like semantics, but the short answer is no, not local/unnamed branches at all, they’s automated extracts of diffs from the developer’s working-copy at a point in time. Long answer:
Google: daemon reaches into you workspace and pulls out the diffs, and stores them a database for posterity. Could be over SSH, could be via NFS. That happens as a developer initiates a submission of the change-list (CL) for review, and essentially it’s a call-back. Mondrian presents those diff to people doing reviews. That’s not actually from a branch, local or remote, its from working-copy, and its a moment it time - the developer could change the working copy afterwards, yet the review stands as it was at the time of it being submitted.
Facebook’s Phabricator is the same when in ‘review’ (vs ‘audit’) mode. Refer Phabricator’s differential user guide. Note too that it is built for Mercurial, Git and Subversion, and the latter has no notion of local branches.
Github’s workflow (for themselves and for the users of Github): Developer makes a fork. That’s very much like a branch, but is a separate repo. Ordinarily only Git repos that are clone/forks of a thing, point back to the original thing. Ordinarily the original thing can’t be asked “who has forks of you”. Of course Github has extra tooling to answer the “who has forked this repo” question. Contrast to real branches - Git can report (for a single repo) what all the branches are called, and commits for each can be subsequently addressed separately. Reviews can happen in Github anywhere. On the original repo, on the fork, and by anyone who can see the repo in question, but that’s an aside.