Paul Hammant's Blog: Cookie Cutter Scaling
It is true that the industry generally no longer does vertical scaling - buying bigger and bigger boxes to host single deployments of nodes in a stack. For many years, horizontal scaling has been the normal scaling technique. There is some variation in the implementations of that idea though. One particular style, where all horizontally scaled nodes are identical (which I’ll call cookie cutter for the sake of this posting) pays dividends in terms of easy deployment and the ability to simply add boxes to add capacity to the stack.
Deliberate Multi-Tier Designs
One common one for enterprises is to have a multi-tier architecture with TCP/IP separating each tier, and each horizontally scaled according to CPU load:
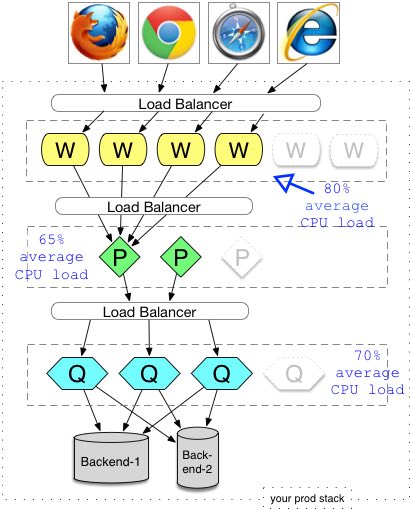
Explanation: In the above, the observed (or estimated) CPU loads of the production environment drive the numbers of each node at each tier. Assuming identical hardware for each process, it is easy to predict how many and where new hardware has to be added for a horizontal increase in capacity. In the diagram above, to denote an intended capacity increase, I have two ghosted nodes at the W (Web) tier, and one ghosted node for each of the P and Q nodes (whatever they are). In our diagram we model two ultimate backends. They could be an big-bucks Oracle DB, ERP or legacy IBM mainframe. They can add their own constraints like a max number of concurrent connections, that would affect everything I’m trying to sell here.
Scaling problem
When the production load on the stack is getting close to the maximums or starting to degrade capacity, then CPU percentage loads can be used as a way to work out which tier needs a new node to alleviate load (the shaded boxes in the diagram). That, or some more complex analysis according to Amdahl’s law. With each deployment in one tier as opposed to another, there are configuration considerations. Lastly, your architecture (and its configuration) might be able to suffer nodes being provisioned while the stack is up, or it might require being taken down totally (like the ‘Apple store’ today, though that might be because of mystique).
Cookie Cut Designs Recommended
The premise is that you compress up as many tiers into the top tier as possible. Optimally into the same process, so you’re avoiding between-machine TCP/IP if you can. This assumes that you are using the same base technology in a relatively homogenous solution. Corporate Java or .Net teams are used to that reality. Quite often startups are not, as they’ll use any technology that’s reasonable to get functionality live quickly. If you cannot get everything inside one process (one Java or .Net VM), then a localhost TCP/IP interface will suffice.
Anyway, here’s a diagrammatic representation of the cookie cutter version of the previous architecture.
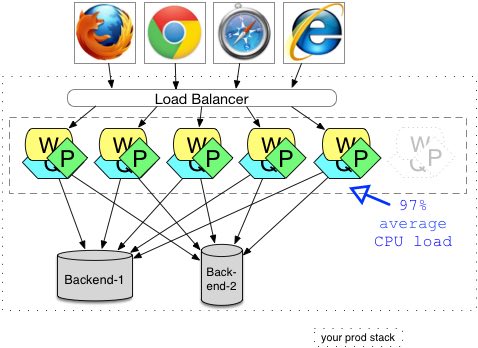
Here we have W, P and Q in in one process. The designers should have drunk the Inversion of Control and Dependency Injection kool-aid to allow a sane structuring of the components of this application, and to minimize the side effects of running multiple things concurrently in one virtual machine. We’ve eliminated some but not all of the downstream calls. With this design we still have to worry about timeouts and caching to a different degree. Other things will become problems that were not before. Specifically we have more classes in one VM (JVM or CLR for .Net) or now, and should worry about getting the memory allocations correctly. Then there is the sidestepping all the TCP/IP formerly involved, as well as the implicit error handling or failover for outage. We should also think about whether there is garbage collection that might have been workable before, but has tipped over a threshold since putting more in one JVM/CLR. Perhaps also, there is dynamic class loading and implicit unloading that could cause the issues like they have for others in the past. The downside could also include reaching the constrains of the big or legacy back-end systems. The mainframe may only be able to support a fixed number of concurrent connections.
In some senses, this is moving ‘functionality via remote services’, to ‘functionality in an embeddable library’. Whereas services can have their own release schedule, and the larger stack need not be deployed in lock-step, embeddable libraries are different. Specifically, if there is a defect in the embeddable library version of the same thing, how quickly can all systems that use it be redeployed. Is your deployment organization adept enough at rolling out upgrades, or are you 18 months at a time with the same release?
Examples
We could consider that verifying Zipcodes or calculating Geo-ip data are candidates for external services, with elegant RESTful interfaces. There would be a team around that of course, and it would get its own release schedule. That would be a traditional enterprise solution right? A sizing exercise would work out how many nodes were required in production, and the release engineers would get busy adding domain names and port numbers to configuration. With the cookie cutter alternative, those two would be deployed in the same process as the things that would use them. You would do some sums to determine whether the added data for each were was worth the cost.
Actually Zipcodes and Geo-IP data are edge-case use in a typical stack. I blogged before about Google Accounts, and maybe Google would do Geo-ip via a redirect on a missing or out of date cookie. At least they are tangible examples though.
Deploying A Cookie Cutter Solution
From the deployer’s point of view, there are far fewer nodes types to think about. If the stack has load-balancing (say F5) in front of the web tier, then registering new nodes with that is the only configuration ‘chore’. In terms of deployment at a pertinent go-live moment, and assuming humans are still involved (versus Continuous Delivery), a slider metaphor may be appropriate:
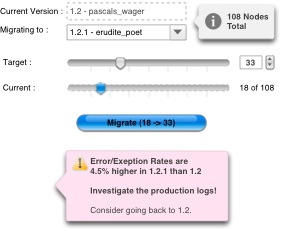
Edging the slider to the right is a safer than an all or nothing flipping of a switch for a release. Using the measured incidence of exceptions from the logs is a good way of gauging the success of the upgrade while 10% of the way in. Of course whether your app is stateful or stateless has a bearing on whether this will work or not. If it is stateful, F5 is going to try to keep people attached to instances hosting the old version. You’re going to have to log session out periodically if their session is inactive, in order to free up nodes. If you use Gmail, you notice that Google logs you our periodically. Sometimes sooner than you’d expect, or two separate gmail accounts get logged out at the same time, and that could be correlated with a upgrade progression like this. If the stack is stateless, then moving folks from one node to another mid-session is far easier. Although, that would only work for releases where there a few discernible differences between the old and the new.
If you ignore CDNs and similar in-house solutions for static content, in terms of hardware you only have one set of machines. Each of those machines is either on one version or another. With the other style of “all upgrade at once” solutions, you will need two sets of machines, if you want to minimize downtime to seconds.
The Developers View
From the developers point of view, there is a chance that they can bring up a larger chunk of the system on their own box. Not only does this help a desk-check of the functionality that is about to be committed, but support folks are going to find it easier to attach an IDE for interactive debugging of issues they are trying to reproduce. Sometimes dev boxes given out in enterprises are particularly powerful. Anything to relieve the amount of resources needed for the processes needed to stand up the stack, would be a good thing. Also, having the production configuration closer to the development config, is a good thing. In a way, this is faithfully scaling the production architecture downwards, to an individual developer.
Caching and Latency Considerations
While this blog entry promotes the simplicity aspects of deploying in a cookie cutter style, there are a couple of other things to think about.
Caching Issues
The designers of the reference multi-tier stack at the top, may have caching in place at any of the tiers to reduce the number of downstream calls. That could either be a separate cache per node because there is only a fixed set of relatively static data (refer to the traditional use of EhCache), or something in a Memcached style design that could support all of the nodes in the same tier. This all amounts to a performance boost to the stack. The suggested cookie-cutter solution can similarly benefit from caching. Depending on the variable range of items being cached, and the numbers of keys, the same caching solutions can apply.
Latency Issues
It is true to say that each physically separated tier in a production stack can add latency to the end-user experience. Caching, as mentioned, can reduce that, but only for transactions that are meaningfully cacheable. What sort of figures can this amount to in a tuned production stack? It can be as low as single-digit milliseconds per tier, and many would argue that this verging on insignificant. What makes the TCP/IP multi-tier physically-separated machine style more complex in terms of design and deployment, is that care has to be taken with timeouts. If the bottom most tier can handle timeouts appropriately, then a tier above that calls it should have a longer time out. Or put another way, the closer to the client (browser) it gets, the longer the timeout should be. Perhaps they should not be inordinately long. Instead a sensible design should occur, with shorter and shorter timeouts towards the bottom of the stack.
Conclusion
Once you have matched your development and deployment practices to the cookie cutter style, you are able to feel the benefits of provisioning interchangeable machines. Not only that, but the flexible resource allocation, automation of server management tasks, far fewer involved deployment engineers should provide additional (smug) comforts :)
PS - Related Blog Entries
I’ve blogged in and around this space for a few months:
The Architectural meaning behind Google’s Accounts system
- Google are likely not calling side systems with every request. There’s a notable exception with Search’s OneBox which is essentially a server-side include. It has to be said that there are less ‘OneBox inserts’ into pages today than in 2006 when the linked blog entry was written. Aggressive caching of the JavaScript fragments no doubt alleviate a lot of the latency that would be implicit otherwise - Google really care about every millisecond in their stack, especially for search.
A forgotten aspect of the Facade Pattern
- Try not to make your stack function like a sewing machine up and down the stack, for a single user transaction.
The Five port rule for stack configuration
- Merge service endpoints and avoid port-centric configuration bloat.
Thanks to..
Charles Haynes and Cosmin Stejerean for comments and fixes.