Paul Hammant's Blog: Stitz's Five port rule for enterprise application dev
Five ports only
At a client, ThoughtWorkers were discussing the maximum allowable ports a team should use when configuring an enterprise application they are making. Jeremy Stitz (no blog) held up a hand an contributed an exasperated “five”. That seemed like a good, if arbitrary, number to define the simplicity we are hoping to encourage here.
The problem we’re trying to solve
A production stack composed of: Multiple machines and multiple process. Each is different, though sometimes there could be duplication because one particular permutation appears to be overloaded when live. There is going to be a lot of configuration for the production stack. Sometimes that config is spread around. Sometimes in is centralized in a single properties or XML file that is supplied to all booting processes. Invariably, the configuration is different in production than it is in any of the development, testing or staging environments. Then there are developer workstations where we should be observing developers bring up a microcosm of the stack before they commit each change, that are different again. The company in question, now needs a whole team to manage configuration. There nothing approaching simplicity or uniformity with such deployments.
More than once a client in my past has managed to deploy cookie-cut zip files to a range of machines and bring them all up to serve all service needs for the tiers above. I’m going to return to this topic in future blog entries, but for now am going to concentrate on one aspect - ports and the configuration thereof .
Sockets versus ports.
The enterprise app that you’re making may have hundreds of deployed nodes. Hopefully this is horizontal rather than vertical, and that you’re driven by easier scaling meaning that many nodes are identical. If you look at your whole stack in production, you may observe hundreds if not thousands of sockets concurrently open. Those could be incoming of outgoing. Understand that we’re not trying to restrict sockets here, thus you can still have your multi-process or multi-machine deployment.
Be reminded that sockets are not ports. Sockets are a software instantiation that’s actually shuttling data back and forth, whereas a port is more of an intention to do something. An app could be listening on a port, with the intention of streaming data via a socket in due course. Similarly outgoing port usage results is sockets being allocated. Here is a good stack overflow question on the topic. Note - ports vs sockets is a fun interview question.
Ports 80 and 443, and OS level ports
Most apps we are making these days are web based. Therefore using ports 80 and 443 is going to bring your available count down to three, if you are trying to hit the five-port rule.
Your apps could well be using ports like SNMP (ports 161, 162) and you might not know it. We are not trying to legislate against the ports your app is inadvertently using, just the ones you state in application configuration (XML, YAML, properties files etc)
Sharing multiple services on one port
Having ‘Zip Code service’ (yes that’s a zipcode, here’s some information about it) handled by an web-server node, that also handles authentication is easy to imagine. They would be two different URLs on the same apparent web server:
http://myserver/zipcode
http://myserver/authentication
Imagine you had need in one stack, to support ZipCodeService 1.0, 1.1 and 2.0 though. These were essentially successive releases of the same thing, but you still need to support all there. Perhaps your application’s own code uses those three versions and sadly cannot be upgraded in lockstep. Perhaps they are used by remote customers who are also not upgrading in lockstep. What you really need to do is bake your differences into URLs (assuming HTTP) and construct a deployed process that can handle the multiplicity of that with ease.
http://myserver/zipcode/1.0
http://myserver/zipcode/1.1
http://myserver/zipcode/2.0
Let us assume Java or C# (.Net) for a second, and each of those three versions of the same thing has binary dependencies that are incompatible. This is not so much the diamond dependency problem, but that is an interesting topic anyway. With Java and .Net you cannot construct a single class path which has duplications on it, let alone incompatible duplications. Well you can, but you should not as the results will not be what you wish for. You are going to have to construct something that allows for incompatible jars/dlls in the same deployed app, that is more sophisticated than a simple classpath.
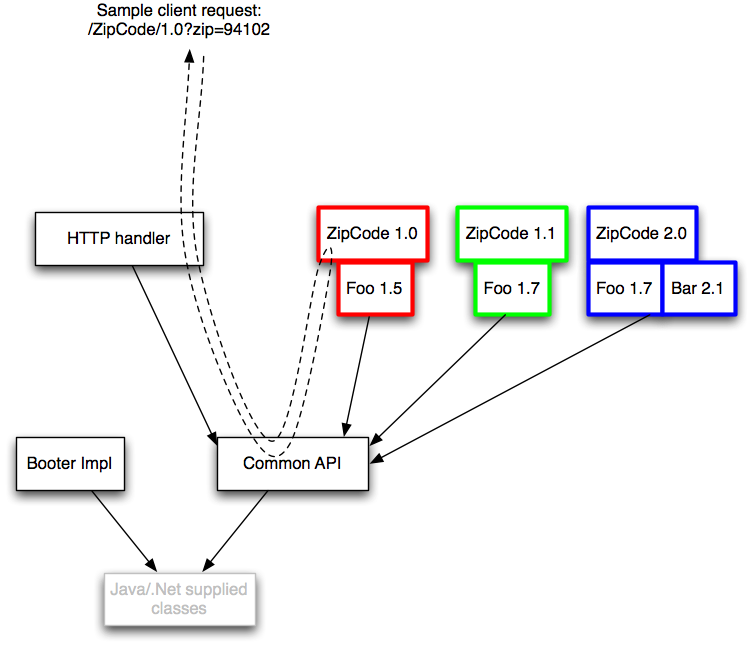
The booter is what constructs this classloader tree. In order it makes the common classloader, the HttpHandler, using the common one as its’s parent, then each of the three zip-code implementations with their respective binary dependencies in the same classloader. Note that there’s a duplicate of an individual jar (it doesn’t matter really).
Once constructed the booter then configures actual endpoints. Think of that stage as more regular Java like so:
handler.register("/zipcode/1.0", new ZipCodeService());
// and the others
handler.startListening();
Except that the booter (which intends itself to be garbage collected as soon as it’s completed its phase) does not see any of the child classloaders directly so will have to use reflection (please imagine the implementation of the fluent helper methods):
Object handler = from(handlerClassloader).make("HttpHandler");
Object zipCode1p0 = from(zipCode1p0Classloader).make("ZipCodeService");
on(handler).invoke("register").with("/zipcode/1.0", zipCode1p0);
Object zipCode1p1 = from(zipCode1p1Classloader).make("ZipCodeService");
on(handler).invoke("register").with("/zipcode/1.1", zipCode1p1);
Object zipCode2p0 = from(zipCode2p0Classloader).make("ZipCodeService");
on(handler).invoke("register").with("/zipcode/2.0", zipCode2p0);
on(handler).invoke("startListening").withNoArgs();
Note also in the diagram that solid lines represent the direction of class visibility. No class in the classloader for ZipCode 1.1 can instantiate any class from its two siblings nor, any class from HttpHandler’s classloader, let alone the one for the booter that should long since be garbage collected by the time the app is running. The booter itself is a special case, as it is the one that constructs the whole classloader tree and temporarily at least has a object reference for all of the classloaders. There are degrees of enthusiasm for hiding the implementation of things that are passed between nodes (like the request)
Java servlet containers (and their capacity to host multiple WAR files) are similar, but we’re defining a common API classloader here that is not itself in amongst Java’s own libraries. In fact our directed graph of classloaders here can be much larger.
Load balancing
Given we’ve now got a single process that can handle everything current and legacy, we might have lost some of the scaling alleged made available from having multiple machines/processes do a single service. The answer is simple - deploy multiple instances of this general purpose services container, and use a regular load balancer to make them appear as one to their clients.
Non-web solutions
Not into RESTfulness? Into CORBA and all that? Sure, this is where you’re going to begin to approach the five ports limit of the title. There are more problems with load-balancing, in that off the shelf solutions for that are tuned for HTTP traffic, but it should be possible engineer a solution where services are somehow named (including versions) within a shared connection of sorts.
Conclusion
I’d much rather compose a directed graph of services that are available for a single cookie cut process deployment, and have a single port number in configuration (80 or 443), than many more ports in play, for many different fine-grained deployments that are listed in some sprawling configuration of machine names and ports. The big-configuration design gets worse when you realize you need one machine for ZipCode service 1.0 and 1.1, but three machines to handle the load of ZipCode service 2.0. Stuff of nightmares; Long live Stitz’s five port rule. 