Paul Hammant's Blog: Depth-first recursive vs DAG build technologies
For many years I’ve been contrasting depth-first recursive build technologies with directed graph types.
In this blog entry I outline then discuss pros and cons
Classic depth-first recursive
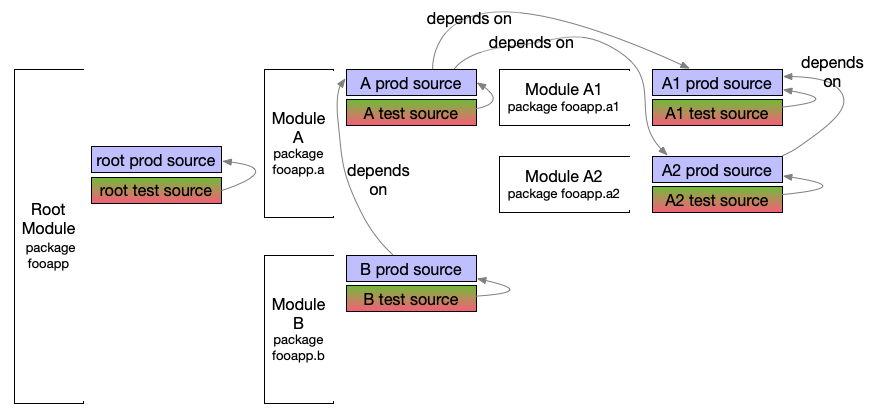
Stylized directory representation
build-file
fooapp/
build-file
src/
prod/
fooapp/ (many source files)
test/
fooapp/ (many source files)
a/
build-file
src/
prod/
fooapp/a/ (many source files)
test/
fooapp/a/ (many source files)
a1/
build-file
src/
prod/
fooapp/a/a1/ (many source files)
test/
fooapp/a/a1/ (many source files)
a2/
build-file
src/
prod/
fooapp/a/a2/ (many source files)
test/
fooapp/a/a2/ (many source files)
b/
build-file
src/
prod/
fooapp/b/ (many source files)
test/
fooapp/b/ (many source files)
If you built a regular ‘compile’ intention from root, the order is: a1 prod source, a2 prod source, a prod source, b prod source, then the root module prod source.
If you built a ‘test’ target/intention from root, the order is:
a1compile prod sourcea1compile test sourcea1test executiona2compile prod sourcea2compile test sourcea2test executionacompile prod sourceacompile test sourceatest executionbcompile prod sourcebcompile test sourcebtest execution- root module compile prod source
- root module compile test source
- root module test execution
Any of those stages failing and if stops right there with output telling you want went wrong.
If you built a ‘binary/package’ target/intention from root, the order is:
a1compile prod sourcea1compile test sourcea1test executiona1binary creationa2compile prod sourcea2compile test sourcea2test executiona2binary creationacompile prod sourceacompile test sourceatest executionabinary creationbcompile prod sourcebcompile test sourcebtest executionbbinary creation- root module compile prod source
- root module compile test source
- root module test execution
- root module binary creation
As before, any of those stages failing and if stops right there with output telling you want went wrong.
Depth-first recursive build technologies validate the entire tree to some degree. Module level deps is the onus for that. As the build kicks off and (say) a1 compilation happens, other classes of dependency may be noted as missing by the language’s compiler at that stage.
Directed graph (Google-style monorepo)
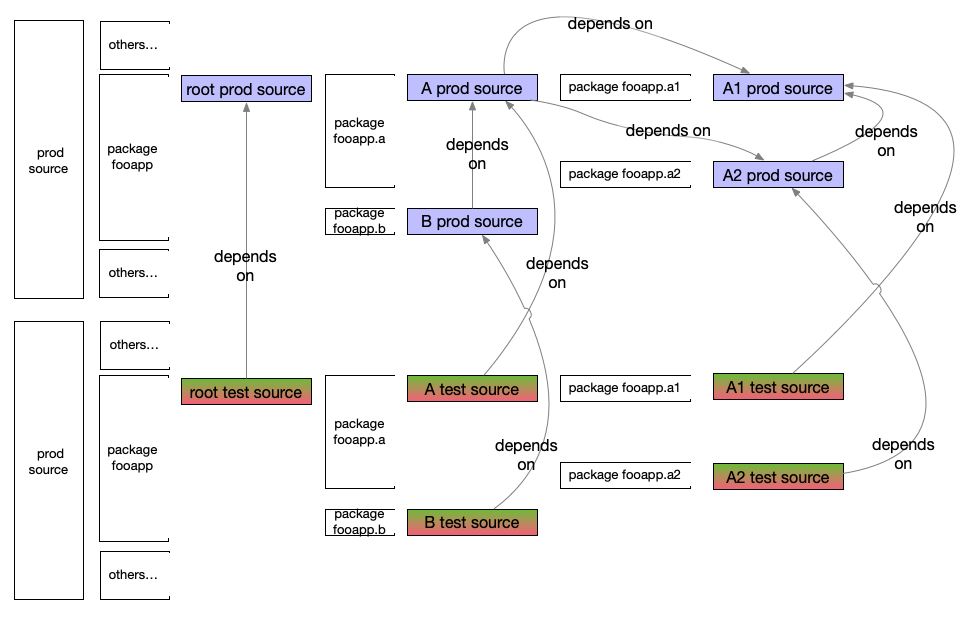
Stylized directory representation
build-file.sh
prod/
fooapp/
build-meta-info
(many source files)
a/
build-meta-info
(many source files)
a1/
build-meta-info
(many source files)
a2/
build-meta-info
(many source files)
b/
build-meta-info
(many source files)
(others)
test/
fooapp/
build-meta-info
(many source files)
a/
build-meta-info
(many source files)
a1/
build-meta-info
(many source files)
a2/
build-meta-info
(many source files)
b/
build-meta-info
(many source files)
(others)
If you built a regular ‘compile’ intention from root, the best case is: prod source for a1, a2, a, and b all compiled together.
If you built a ‘test’ target/intention from root, the best case order is:
- prod source for
a1,a2,a,band the root module all compiled together - test source for
a1,a2,a,band the root module all compiled together - test execution of
a1,a2,a,band the root module all together
If you built a ‘binary/package’ target/intention from root, the order is those three above and:
- binary created for shippable/deployable root module
fooappand it’s deps (a,a1,a2&b… also third party deps, but we’re not going into that today)
Directed graph build systems can validate the graph of dependencies without compilation. For example, a source file may have an import/using/include of fooapp/z/Zed.java and nowhere in the current set of declared dependencies is that found. The invalidity can be flagged to the developer sooner: the build-meta-info should be updated to include the dep (source of binary). Likewise, a dependency in the build-meta-info might not be needed, and it is possible to get the build technology to report too: you’d take that out, maybe.
Compared
Note: “build” to me doesn’t just mean compile when I use it without qualifier. It means compile AND all impacted tests AND package steps.
The depth-first recursive build technologies can have optional parameters for larger traversals from root.
- skip all tests, but still make the binary/binaries
- only run tests that match a specific pattern - a subset of all tests, or maybe just a single test
The depth-first recursive build technologies allow you to do an initial full build of everything, then cd into a sub dir for a more focussed set of activities: cd a/a2; #build commands now affect that that module
Directed graph build technologies can ALSO work with classic modular source tree layout (more common with depth-first recursive). That would leverage a depth-first traversal that is more in line with that class of build tech. Purists would say this is second class.
Directed graph build systems classically work from the root of the checkout: build-command tests a/a2/* would compile a1 and a2, then execute the tests in a2 (and nothing else). It is a key feature of these technologies that they skip source directories that are not pertinent to the target. In Google ‘adsense’ and ‘adwords’ were adjacent Java packages in both the prod source tree and the test source tree. Your checkout could have one or both - you blaze target would ignore source present on your filesystem in directories (packages for Java) if the target didn’t need it. By contrast, if a directed graph build system steps into a module compile is going to happen for all present (subject to cache) without exclusions of packages within.
Both systems could leverage a build cache and not repeat compile steps for modules that have already been compiles for the sources in question. Not all build technologies have nailed the repeatability needed to implement this.
Circular references
Do either of the two allow for circular references?
No, not at the module level where a thing is buildable on its own or has build meta info. Both classes of build technology fail early in an attempt to do compile, test, or package.
Some languages do allow circular references. e.g. Laurel.java can depend on Hardy.java which can depend on Laurel.java but that’s a different thing and can only happen in one javac invocation (one module)
Note: Directed acyclic graph (DAG) applies in this context to what I am titling “directed graph build techs”.
Running impacted tests only
I wrote for Martin Fowler’s ‘bliki’: The Rise of Test Impact Analysis (2017). This is about shorter build times that are still provably sufficient.
Directed graph build systems can target impacted tests far more easily using build-meta-info that’s already in the source tree. Sure if that meta info is a multi-year mess, then impacted tests only might be a mirage.
For depth-first recursive build technologies it’s harder to implement this capability. Indeed, it may require training to calculate the maps. Training would be non-CI repeated runs of builds, and the resulting meta info requires storage in order to be used by the team. I would say inside VCS and co-located with the modules it pertains to, but then I’m obsession with source-control as a backing store.
Subsetting the checkout (expand/contract)
Blog entries:
Directed graph build systems can casually skip modules present in the file system, but not implicated in the build target. Google’s in-house Blaze can remove the unneeded directories or add them with simple commands. The build target execution time doesn’t change but the number of source files can be reduced speeding up your chosen IDE.
I attempted to do something similar for Java’s Maven build-tech and Git. Blog entry Further Experiments With Expanding/Contracting Monorepos (2017).
Directed graph build-tech choices
| Tech | Years | Open source | expand/contract | Build-in 3GL # | Community 3GL # |
|---|---|---|---|---|---|
| Blaze | 2004 - | No, inside Google | yes | 5+ | |
| Bazel | 2010 - | Yes | 14 | 8 | |
| Nx | 2018 - | Yes | 2 | 2 | |
| Pants 1 | 2012 - 2021 | Yes | 4 | ||
| Pants 2 | 2020 | Yes | 4 | ||
| Please | 2016 | Yes | 4 | ||
| Lage | Yes | ? | |||
| Rush | Yes | 2 (JS & TS) | |||
| Turborepo | 2021 - | Yes | 2 (JS & TS) | ||
| Buck | 2013 - | Yes | 15 |
TODO: help me fill these in folks ==> paul@hammant.org