Paul Hammant's Blog: Trunk, CI, Builds, Environments, and Integration
At a certain level of accomplishment a dev team has become adept at using build infrastructure to lock in their ‘Continuous Integration’ (CI) achievements. Martin Fowler pointed out “[…] It is only Continuous Integration if it’s run on a shared mainline that people commit to every day. Running such a daemon otherwise, such as on every FeatureBranch, is Daemonic Continuous Integration that debases the name.”. Thus, CI is greatly overused as a term in the industry. Note: Martin’s ContinuousIntegrationCertification bliki entry has been expanded and reworded slightly since original publication, and doesn’t have that punchy statement anymore :-(
Nirvana is where teams are truly doing Continuous Deployment (CD) into production. They are not slowing themselves down with branches. Well, ignore the short-lived feature branches of Pull Requests, that is.
For everyone else branches are a bigger factor. Here’s a typical modern branching model with overlaid build automation bits and pieces:
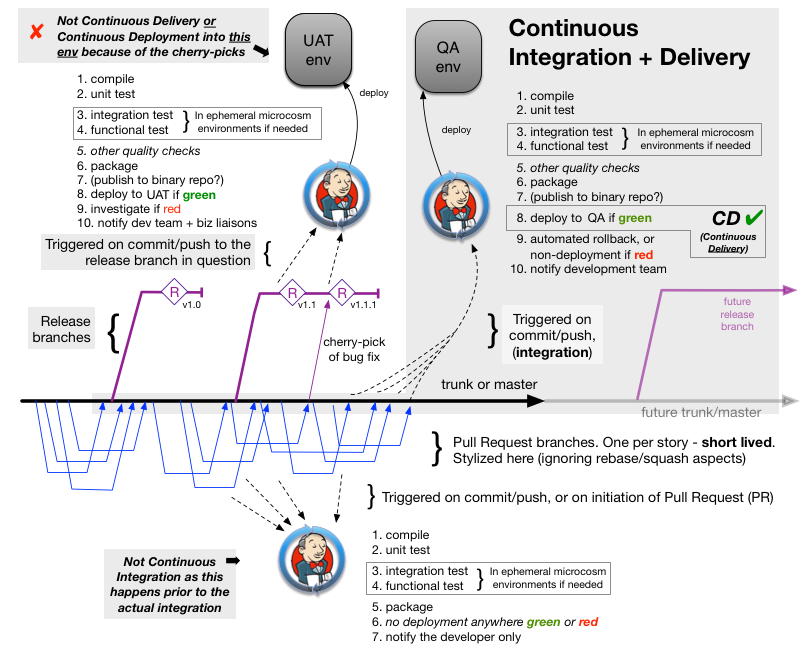
In the diagram above, the team has three separate usages of the build infrastructure. One is testing the work that is prior to integration into trunk or master. That is a commit/push as normal but to short-lived pull-request (PR) branches. If the dev team is 20 strong, and that work was from one developer, there are 19 that do not need to be alerted to the fact that one of them committed and pushed something that broke the build. While the work on that PR branch should not go any further before it is fixed, that’s a fact that can be communicated in the web-UI for the pull-request workflow. It is important to note that no-rollback of the commit is needed for failures here as the other developers are not depending on the PR branches of a colleague.
Another is taking the very infrequent cherry-pick merges to release branches and running roughly the same automated build steps and technology, but with the additional step of deployment to an environment. In the diagram above, that is UAT as QA has already been deployed to by the CI build. If this build fails (statistically unlikely), then it does not have to be rolled back, as there is always only one developer being a responsible adult with a “merge meister” hat on taking approved cherry picks towards release branches. Specifically, “roll forward” is fine once someone works out why that build failed. It can’t be left broken, of course.
The third is the one that picks up pushes of commits to trunk/master and runs them though the same builds steps. That one is the only one of the three build-bot processes described here (Jenkins depicted in the diagram) that is actually Continuous Integration (CI). The other two are not CI even if the infra to perform them is shared. So, with this CI use of Jenkins a build failure is a bad thing. Most likely you’ll automate the roll-back of that commit in the seconds following the build breakage determination, and force the problem of getting it through code-review (etc) again to the original developer.
In terms of language “Integration” is the act of landing commits in trunk or master for all to see, and in a way that the humans involved have a high confidence that the commits are great. Specifically if the CI build fails then that should be a huge surprise, and have some random or bad-timing factor perhaps as the cause of that. Elsewhere in the industry there are many teams that half expect something to fail in that consequential build, or won’t know if it has failed until the next morning. Those are teams are not doing CI. While “merge”, on some basis, is the action with VCS tools to actually land those commits, it is “integration” that is the useful descriptor for the action and intention when it is going into the branch the whole-team shares (trunk or master).
Something worth reminding
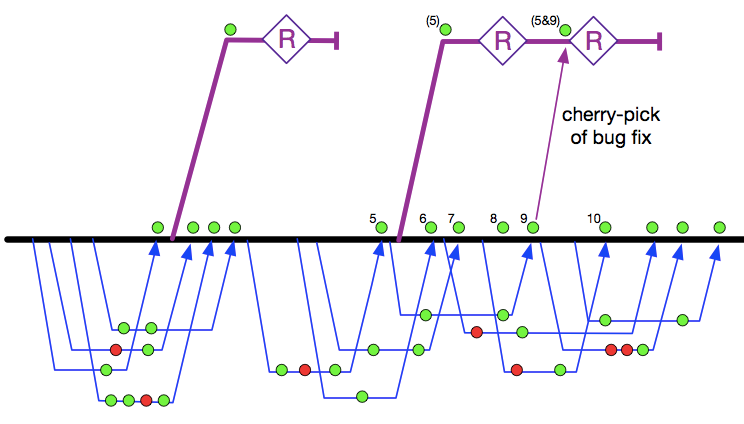
In Trunk-Based Development release branches are created ahead of the release(s) that they are pertinent to. They are not merely reflective of a release that has already gone out. For adept teams creation is a few days ahead, and for lower cadence teams as much as a week. As for all branches, there is an underlying policy that drives the rationale (or should be). In this case we want a freeze, but not to the branch the developers are most active (the trunk or master). We’re ensuring that the release is ready (production hardening) and that requires keeping developers out. They can firehose into trunk/master if they like (one commit every few seconds in Google), but that release branch is a place where the list of commits making it into prod is stable. And when we decide that the branch contains a bug (can be discovered pre or post release), we fix it in trunk and cherry-pick it to the release branch. We do that because we do not want everything else that was firehosed onto trunk/master to merge into the release branch too. Hence the ‘5&9’ label in the second release branch. Oh and release branches, like short-lived-feature branches get deleted after a while.
New build-infra frontiers
Many teams are able to use the build infrastructure tactically to verify partially complete work on a dev work station. This may or may not have been committed yet, but it certainly has not been pushed to any team observable place in the branch diagrams above. Specifically not to the pull-request branches (short-lived-feature branches). The use of build-infra could be Selenium nodes via “Selenium Hub”, but it could also be something closer to “the full build” if required. Specifically the changes are snapshotted somehow and handed to the build infra to run elsewhere while the developer pushes ahead with what they are working on. I.e the news will come back “would or would not break the build if commit/pushed”. For a few years now, developers have been able to run technologies on their workstation that ran tests as they typed, but there are some build steps where that is impractical so the “snapshot and run elsewhere” capability is needed.
More on policies for (release) branch creation
“Branch: only when necessary, on incompatible policy, late, and instead of freeze”
— Laura Wingerd & Christopher Seiwald
(1998’s High-Level SCM Best Practices white paper)
The freeze aspect is key here. We do not want to freeze the trunk because that is where all developer’s commits are landing in quick succession (directly for v small teams, or more likely through pull-request mechanisms these days). We don’t even want to freeze it at any moment before a production release even temporarily. Instead we freeze the branch we make from the trunk. We do that with three mechanisms, when create the branch:
- We do not use an ordinary merge to take all commits on trunk made since the release branch was created to the branch
- We also don’t admit the core of developers to that branch (in fact we completely lock out their ability to commit there)
- Lastly we have controls around merges to the release branch because we only want genuine bug fixes there, and not “late” feature development (resist those business people and PMs!). Specifically we allow cherry-picks (a specific type of merge), and we keep a non-repudiable list of the approvals received for each
The short-lived feature branches uses are for temporary individual developer isolation from trunk, the pull-request and code review before merging into trunk? They’re different. Indeed, in Google in the mid 2000’s (perhaps 8,000 committers in one trunk) they were not branches at all, they were curated patch sets that facilitated many possibilities. This because Perforce did not have very lightweight branches.
The ‘late’ and ‘incompatible policy’ are correct. If you’re doing release branches make them at the last responsible moment before the release itself. If you need user sign-off for that release from UAT, then accommodate that. Do not make release branches early in each release cycle - though I’ve never heard that suggested by anyone who gets Trunk Based Development. The defining incompatible policy is that the release branch must tend towards stability (the trunk never will unless your org stops paying for developers and QAs).
Updates:
-
Jan 8th, 2018: spelling and clarification.
-
Jan 19, 2019: Martin changed the language on ‘certification’ bliki entry.