Paul Hammant's Blog: CI, Breaking Builds, Bisecting, And Reverting
Revert On Red (build breakage)?
A few days ago Henry Lawson asks when you should revert a commit if the build breaks: Revert On Red. (there was a Reddit discussion too) - a real problem for many enterprises trying to push ahead with DevOps things, and worth bringing up for discussion. In the Reddit discussion, Henry links off to a relevent Martin Fowler artile, and ex-colleage Andrew Care dives in too, with some solid insights.
The answer is really a function of how many people commit to the same branch/trunk, how often a day they commit, how often the build breaks, how long the build takes, and what tooling you’ve done to accelerate build-breakage news dissemination.
A Tiny Team
At the lower end, a team of 5 people each committing once or twice a day, could easily take a “let’s investigate” attitude to build-breakage. That team could do a commit that follows the break to fix it. They might not even have a Continuous Integration daemon (like Jenkins), even if they are doing Trunk-Based Development. A build breakage, for that team, might be something that’s determined from a developer workstation by a human, within earshot of other developers.
Many thousands divided into many teams
At the higher end, you’re always going to auto-revert the first commit that breaks a build. The higher end could be like Google’s 20,000 developers in one big trunk. Proving which commit to revert is non-trivial that that situation. I say that because trunk might be going forwards at one commit a second, and all builds take between one minute and fifteen to complete (or fail). In this case a sequence of 300 builds might all go red after you discover the break (red build) out of order because they were all running in parallel in a scaled cloudy infrastructure. If they were running in series, you’d never keep up with one commit a second. It’s only the earliest one that you want to revert, so if there are any earlier commits still running, you should delay your auto-rollback determination until you’re absolutely sure which one. Delay in this parallelizd design meen minutes. After the applicable robot made that determination and did the revert, the other 299 builds need to be kicked off again to make sure they did not separately break the build too. That is probably 599 commits by now. For Google, that situation is exceptionally rare - they separately verify the pending commit before it arrives in a place that the other 19999 developers could pull/sync it. It’s only unfortunate timing of two commits that could possibly cause a break. Key to their “the build never breaks” success, is their use of Blaze (Bazel in its open source guise) which is a directed graph build system that ties classes to test classes much more tightly that historical build systems.
Somewhere in between?
Of course, your enterprise is somewhere between these two places. You are not Google, and you have basic CI which at best batches up many commits per build job - meaning one of say twenty commits broke the build, and it is going to take some sleuthing to work out which one.
Bisecting Towards The Commit That Broke The Build.
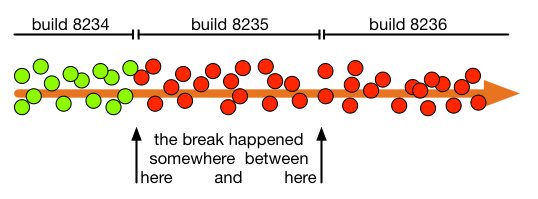
It does not matter whether your source-control tool has bisect (a binary search capability) built in or not, the process is quite easy to understand. Somewhere between the last known good commit, and the most recent commit amongst the batch of commits that the CI daemon first determined are broken, is the causal break. That is one of the commits in build 8235, in the diagram above. You need to hone in on it before you can revert it. To find out which one it is: Go half in that sequence, test that, go half way back or forwards from there based on the test you did being red or green, and continue until you identify the actual breaking commit. Maybe that is a one person job. Maybe a few people take a different commit to test, but that is much less methodical, even if it is potentially faster. Everyone in a dev team should know how to bisect, and be prepared to do it if requested.
Even after all that, you still need to determine whether rolling it back is best or not. You probably have time to try rolling it back in your dev workstation’s workspace while also compiling and testing all the following commits. I mean you have time to predict ultimate CI red or greenness, before doing the actual commit/push. That is a high-confidence prediction, as you expect the CI daemon to rubber stamp what you determined on your workstation, given you moved up to HEAD.
Git’s bisect came in handy for me today. Something subtly broke a few months ago. I was able to identify one good build from back then, and knew that now was bad. It took three commands and 90 seconds for each iteration, so it wasn’t costly to do the six or so steps to get back to root cause. As it happens, that was not a revert - too much change since dependend on that precise commit. It is at least data that feeds into work that fixes the subtle break at HEAD, and introduces a test to make sure it does not happen again.
Trunk-Based Development and Continuous Integration
Some skinny definitions:
Continuous Integration (CI)
CI is an intention for a development team: Wikipedia -
“Continuous integration is the practice, in software engineering, of merging all developer working copies to a shared mainline several times a day. It was first named and proposed by Grady Booch in his 1991 method, although Booch did not advocate integrating several times a day. It was adopted as part of extreme programming (XP), which did advocate integrating more than once per day, perhaps as many as tens of times per day.
Martin Fowler and Matt Foemmel’s original article on CI (September 2000) is worth a read, though the expanded 2006 version is better.
Continuous Integration Daemons
Continuous Integration Daemons (like Jenkins) are servers that purport to deliver on the promise of Continuous Integration. They verify commits made to a source-control system are all good: the “build” passes. Apache’s Gump was an early CI daemon (1999), and it concentrated on verifying that multiple Apache projects that built jars, would work with sibling projects that also built jars (many interdependencies). Not only jars of course, and not only Apache projects. It was an early warning system for incompatibilities. At Apache, each projects’ own leads set direction, and that could include backward incompatible changes. Something like Gump is invaluable, if incredibly daunting in terms of permutations.
A couple of years later CruiseControl was launched for enterprise developers. It was similar enough to Gump, but a lot more installable, and much more well known. A few years after that, Jenkins (originally Hudson) took over from CruiseControl. It had a polished user interface, but did not store its configuration in source control (sadly). There’s been an explosion since - SaaS too.
Trunk-Based Development (TBD)
TBD focuses on the source-control practices. Have one trunk; Don’t make branches you intend developers to commit to over time. Branch by Abstraction (BbA) was always part of TBD, even if it only gained a name later. Feature toggles/flags too. For teams not doing BbA, a technique leveraging #ifdef, #else, #endif (and equivalents) was how you effected longer-to-achieve changes in a single branch/trunk. Inferior of course. TBD is really about branching, merging, and your fine-grained enthusiasm for those.
Adaptations
TBD has had to adapt over the years. The advent of Git, and Pull-Requests that are effectively organized on a branch, the only remaining concern is how long that branch lives before it can be deleted, and how many developers contributed to it. You hope (or mandate) just one pair and for just one day. You try to remind people that lengthening the life of a “one day I promise” branch, risks it becoming a sunk cost fallacy trainwreck. At the start of the article, I alluded to a Martin Fowler article that Henry linked to - here it is “Pending Head” and it is worth a read, because it chronicles the experiments that came before a Pull Requests became a mainstream SCM feature.
Google’s Big Trunk
Google scaled their trunk to 20,000 developers (as mentioned), and they share code (dependencies) at source level, while allowing devs to not checkout anything unrelated to the application or service that would go into production on some cadence. There’s no doubt at all that this is the highest-throughput configuration of 20,000 developers: hats off to Google.
Sharing binary dependencies is inferior versus Googles way: sharing at source level with a composite checkout. Having used it, I dream of that tooling being made readily accessible. Amongst many benefits, the ability to do atomic commits (and atomic rollbacks) stands out, especially as you consider you’re never losing history for sophisticated refactorings. That compared to moving code from repo1 to repo2, and that being two commits, and potentially two nudges for two CI daemons.
Trunk-Based Development vs Continuous Integration
A gratuitous Venn diagram:
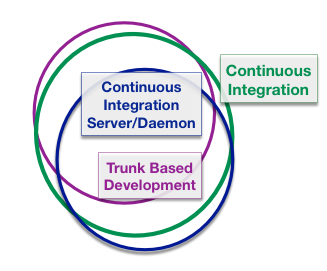
Continuous Integration is a practice that purports to encompass Trunk-Based Development. You know this because the modern translation of “merging all developer working copies to a shared mainline” is “a single trunk’, despite the science and advances of source-control being almost entirely defined after Grady Booch’s 1991 OOAD book.
Continuous Integration (CI) is inextricably linked with Continuous Integration Daemons, though. Notable implementations included CruiseControl 13 years ago (from ThoughtWorks), and Hudson/Jenkins 10 years ago (and still a force). Indeed most people think of a Jenkins-like server when you say CI. Just look at the original Wikipedia page for evidence of that. Moreover with an explosion of choices for in that field after Jenkins became the enterprise gorilla, means that multi-branch development can be aggressively guarded by CI daemons. Deliberate multi-branch development is not CI at all (I mean the original intent) yet it is popular.
Back to TBD again. As mentioned before, it possible to do TBD without a CI server/daemon guarding your commits at all.
Mono Repo versus One Big Trunk
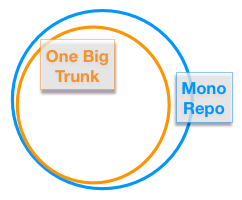
Of course you can do a trunk based development model on your 22 smaller Github repositories. Binaries output from one, could be the input for another. So “MonoRepo” is a meme in the last couple of years, driven by details of Googles and Facebook’s large repos. It is unfortunate as what is really valuable is the single, large branch (a trunk) to which all developers directly contribute. The destincion is key, as MonoRepo could have any branch design (in practice nobody does). Some companies like Pixar and Nvidia may have incredibly large trees of files in a single repo, but these a bunch of a dissimilar files that have no merge connotation with other parts of the tree. Thats definitely a MonoRepo usage, but not Trunk-Based Development. OneBigTrunk teams may make a branch (hopefully lightweight) to support a prior release, if they’re not doing a roll-forward strategy for production bugs - branches are not totally avoided.
One last thing
Martin mentioned his Semantic Diffusion bliki article recently. There are a few names of things above that are moving in terms of meaning over time. They’ll move some more. I remember the late 90’s when developers had used only two SCM tools, and both were bad. Say CVS and VSS. They’d hang on to the less bad one, like their life dependend on it, and not be open to a third. Opinions as to what is acceptable move over time, names for the best practices are going to do so too.
Update: Survery turns up CI misunderstanding
(Nov 20th, 2016)
A study ThoughtWorks commissioned, a few months ago turned up the fact that the surveyed group of people mostly differed when asked on what Continuous Integration. At least versus the original definition of the term. I tweeted the same day, back July:
90% survey participants who said they were practising CI, missed the need to integrate to 'trunk' daily (paraphrase) https://t.co/yMV1bZSHBl
— Paul Hammant (@paul_hammant) July 28, 2016
My Tweet indirectly linked to a Snap-CI blog entry by Emily Luke and Suzie Prince: No One Agrees How to Define CI or CD.
In short 90% of people spoken to, were effectively saying:
“Yes we have a piece of software doing continuous integration, but don’t commit/push to a single master/trunk/mainline often”,
Note - As mentioned before, relying on Pull Request branches (if consumed as a priority that were not more than a day in the making) is still faithful to Trunk-Based Development.
There’s more nuggets in the TW article, so it’s worth reading fully, but here’s their footnote on the standard definition of Continuous Integration:
Our standard definition for continuous integration in this study was set as “Everyone merges to mainline/master/trunk at least once a day. Each merge is built and tested on an integration machine.”
So it turns out that Continuous Integration is in fact popularly linked with Continuous Integration daemons and not at anything to do with a single anointed master/trunk/mainline in SCM, in the views of those claiming to do it.