Paul Hammant's Blog: So you think monolith is the only alternative to microservices
The Microservices community is keen to paint the non-microservies architectures as “monoliths”. This is a false dichotomy, as many have said. I’ll make my attempt at explaining why so.

Context
I started in 1989 as a professional programmer on IBM Minicomputers enhancing (and bug fixing) systems that were monolithic. Everything a company needed to function for its operations in one machine, and although modular (by some definition), all had to be upgraded at the same time. We didn’t even really have version control back then. Those systems were also before OO (for the vast majority of enterprise devs), components, discrete services, and Java. The companies whole “system” was on that box. It was upgraded in one go - typically in a big-bang moment that took a weekend, and was prepared waterfall-style over the preceding eighteen months. That was a monolith.
Martin Fowler on Microservices
In my old life in ThoughtWorks, my chief Scientist Martin Fowler got to define concepts (sometimes) and recap/distill (often) for the software community. Martin did a presentation at the fantastic GOTO conference in November (uploaded in January). It is a great objective summary of Microservices. He mentiones cookie cutter in passing, and that is one of my passions. So here I am, with an elaboration on the topic.
Recapping the types of modern deployment
1. Services: horizontally scaled per-service
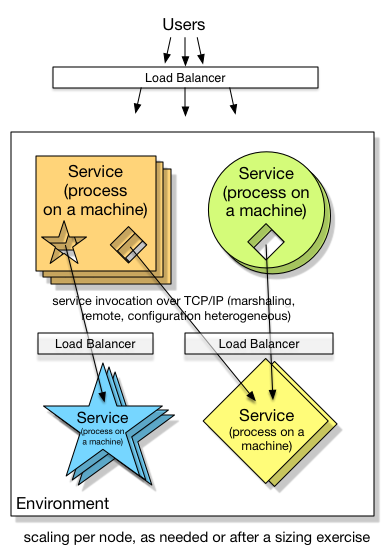
Important Aspects:
- Configuration could be complicated:
salestax01.prod.example.com:4444,salestax01.prod.example.com:5555,salestax02.prod.example.com:4444(round robin), or simpler if a load-balancer and self-registration is the case. - CPU and RAM optimized to the nth degree per service.
- SOA and Microservices advocates recognize this design
- Infrastructure as code is a must
Variations:
- The load balancer could be per service, or one for all services in the environment, or a mix of the two.
- Load balancers may effectively spin up new subordinated nodes, as demand dictates
- Docker-style process containers may figure (one process per machine)
- A machine may have more than one process (non-docker)
- A machine is more likely to be virtual, however it’s not impossible to be a physical machine design
2. Services: cookie cutter scaled
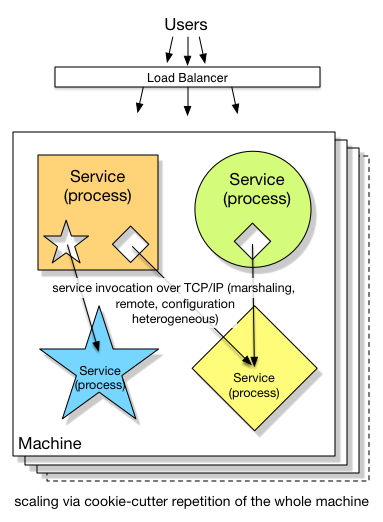
Important Aspects:
- Configuration is more predictable - everything is
localhost:predictablePortNumfor each machine, whether QA, UAT or Production. - Fixed CPU and RAM on per-machine basis, including the potential for arguably wasted allocation.
- Infrastructure as code, again.
- Requests stay within the same machine as much as possible. Perhaps IPC sockets are a performance boost over regular TCP/IP.
- Technologies involved can be heterogeneous.
- say Java, Ruby, Go, Rust, Perl
- You still might have a non-horizontally scaled thing in a lower tier. Say a sparse, distributed multi-dimensional sorted map
3. Components: cookie cutter scaled
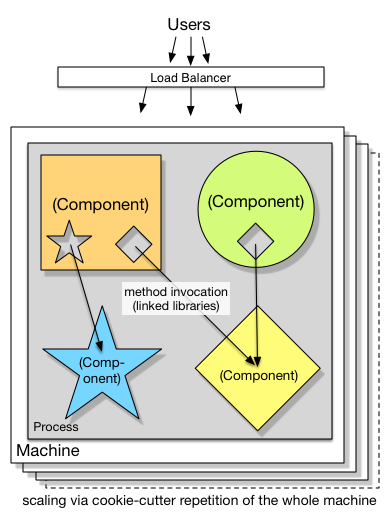
Important Aspects:
- Technologies involved are mostly homogenous
- say JVM technologies like Java, JRuby, Jython, Groovy, Scala and Clojure
- or CLR technologies like C#, F# and IronPython
- maybe including C++ libraries via JNI or P/Invoke
- Spring or Tomcat-style component containers may figure, or may not
- Dependencies defined in code for Classes/methods in a strongly-typed way (preferable to XML)
4. True Monoliths.
(well at least those Mini computer solutions from the early 90’s)
Well the connecting fo shapes metaphor breaks down a little, but you get the point hopefully.
Drilling into cookie-cutter architectures

You only cookie cutter scale a single application. Two applications means two different cookie-cutter shapes and two different horizontal series of deployments. That is true even if they share code/components (or services).
Let’s take two of Google’s applications, pretend they are cookie-cutter scaled and elaborate how that would work: AdSense and AdWords. Let us suggest that they have some percentage of common code too. AdSense would be deployed in its own cookie cutter series, on its own release cadence. AdWords, with a different cadence, would have a different cookie cutter and a different production deployment series. Not the same VMs at all. Neither of those two would invoke any lower-tier services, in the cookie cutter style. Instead they are all bundled with the services or components that they need to invoke. Sure, in Google there’s a single multi-dimensional store called Big Table underneath, and that is definitely shared infrastructure.
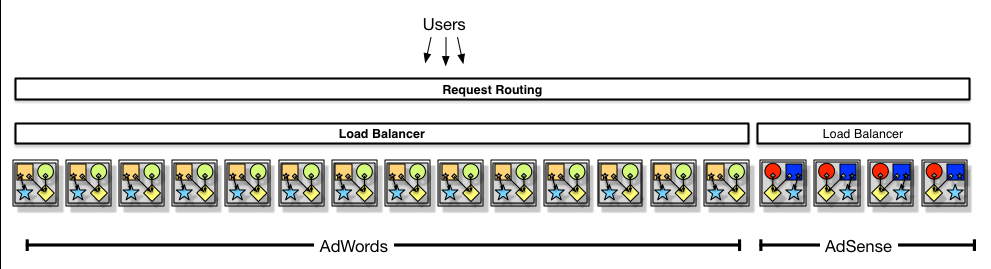
If both AdSense and AdWords needed a “SalesTax” component or service, both would deploy with the compiled code for that. As Google practices trunk-based-development, that pretty much means the HEAD revision of SalesTax at the time of deployment. That means that for AdSense and AdWords in production at any moment in time, they might have different versions of the SalesTax component. Temporarily so, or leapfrogging, it’s all the same - it is whatever was (more or less) at HEAD revision at the time of release. Trunk-Based Development facilitates that particular deployment mechanism very well. If the SalesTax component (or service) is included into the cookie-cutter solution, then there’s no version number (of the API) applicable. No version number if necessary because Continuous Integration tested everything at HEAD revision together in hundreds if not thousands of times, in the run up to the release. The underlying BigTable records for SalesTax probably have to be backwards/forwards compatible for a couple of versions of the SalesTax service or component, but no more. I am assuming that the only consumers of the SalesTax component/service are within all within Google, making it easy to do lock-step upgrades and cookie-cutter scaling. Sometimes that is not always the case, service APIs can be published for use outside the company.
Now, as we look the above AdSense & Adwords team-separated and deployment-separated deployment style, that is in no way microservices and in no way monolith. Therefore microservices advocates - please stop saying the alternative to microservices is monolith.
Incidentally, I have no idea whether AdSense or AdWords have any need for a SalesTax component, or what that would do.