Paul Hammant's Blog: Shades of Trunk-Based Development
I’m going to try to explain the alternatives for Trunk-Based Development (TBD) in terms of branch layout. There’s few different styles, that different types of development organization might to implement.
Make branches for a release (just in time)
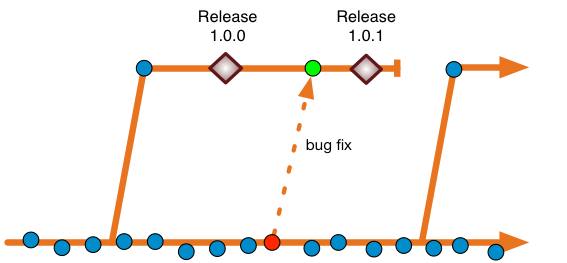
All developers work on the trunk (theirs are the blue commits). Just before a release, a branch is cut for that release. That’s probably a release engineer, and you might change permissions for that branch so that the larger group of developers cannot commit to it even if they can see the branch. The first commits on that branch, by the release engineers, might be to make it ready for release. The release is build from there. Most likely that’s by the same CI technology you were already using (say Jenkins) and it pushes a binary into an repository for ultimate certification and release (also for posterity).
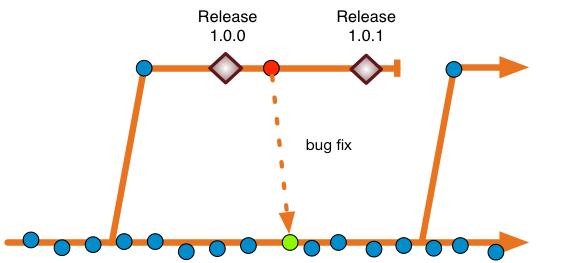
A defect in production
The defect is found after release. Indeed, the trunk (which had no code-freeze whatsoever) has already moved past release. The organization in question does not want to release a new version of the product with the latest commits on trunk, so it has to release something from the pre-existing release branch.
The development does not sweat that the trunk is more advanced than the release. They give it a go trying to fix bug in the trunk (the red commit). There’s a fair chance that if they can reproduce it, fix it, and get QA agreement that it’s fixed on the trunk, then a cherry-pick (of the whole commit) to the release branch will merge just fine (the green commit). If it doesn’t then, some merge resolution might be needed. The remediation of the bug is again agreed by QA, and a point release goes out from the release branch.
Fix on trunk, and cherry-pick to the release branch is the way we guarantee that regressions (bad) don’t happen. Regressions (bad) should not be confused with regression testing (good) of course.
Release from trunk, make a branch to support a release
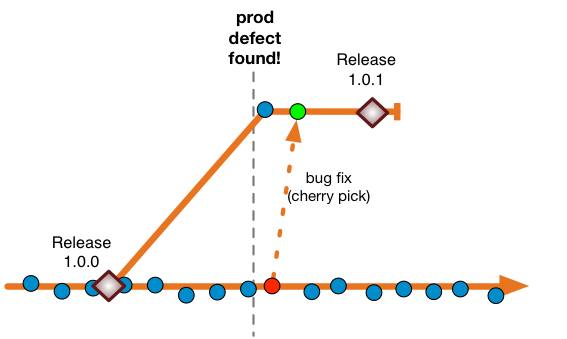
Though the trunk has moved past the commit that’s intended to go live, the release engineers are going to make a tag for that commit, build a binary, and push it towards release. Maybe Jenkins had already made that binary, and it’s certification over a few days is just fine. The developers, again, did not experience a code-freeze.
A defect in production
Long after the event, a branch is created from the tag. It’s as if the branch were created in the style above of course. Everything after the branch creation is as before.
Release from trunk, roll forward
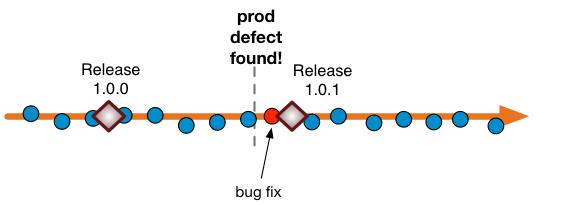
This organization is willing to put code live ahead of schedule, in the event of a defect. They probably have enough feature-toggles and build switches to make sure that features do not go live ahead of schedule. There is no release branch, even in the event of a defect. Even though the team is not continuously deploying, the “next release” is always going to be from trunk. Even for bug-fixes, which don’t need to be merged anywhere.
Release from master, bug fixed on temporary task branch
This is more the style of the pull-request systems that has been popularized by DVCS source-control systems like Git and Mercurial, whereas those above are more the preserve of Subversion and Perforce.
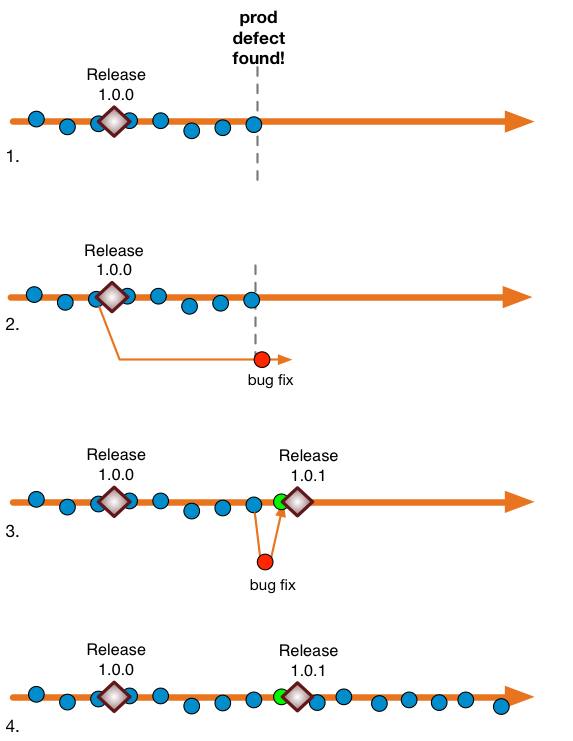
Developers in the team work on lightweight forks of the master (trunk), and submit their pull request when their task is finished. In this case, we’re modeling a bug-fix (#1), so the developer may deliberately reset the working copy to the same commit as that of the defect (#2) and make a lightweight local branch. Going back to the last commit that made the release is optional, as the outcomes can be the same. The defect is fixed, the developer brings themselves up to date (#3) merging if they have to, then issue the pull request as they publish the temporary task branch. They or someone else merges it into the master (trunk), maybe after a code review, and delete the transient work branch. Deletion of the task branch in a DVCS system is as if the branch had never been created (#4) - all incremental history is kept by default and the fact that a branch was created for the work is irrelevant. The release goes out from there as usual. This is also a roll-forward way of doing things.
The communities in question don’t conventionally refer to this model as Trunk-Based Development. Perhaps because of “master” rather than “trunk” being the main branch. Perhaps because Linus had a you just don’t get it speech at Google in 2007 re Git versus their TBD way of working. Perhaps they’d be happier calling the model Master Based Development, or Master Rebased Development, but neither name precludes multi-person non-transient branches that TBD is against, and DVCS embraces via many published workflows.
Fixing defects on the release branch
I really don’t recommend this, as theres a risk of regression (bad). Developers fix the defect on the release branch and merge it back to the trunk. What if they forget though? If the team cuts another branch in the future, that unmerged prior fix now reappears as a regression, and the team gets embarrassed on some large scale. Maybe someone loses a job. Of course, you could guard against unmerged code systematically, but that’s harder to do when some changes should not be merged back to the trunk (things to do with the release itself). There are ways of merging that don’t bring changes with them, but otherwise mark the merges as done.
Branch models with more branches represented
More branches that I’m showing above? Those models are not Trunk-Based Development. They may be branching models that feature a branch called “trunk”, but they are not TBD. ClearCase popularized a “mainline” model, where many developers worked on each branch. Those models are also possible with any of the more modern choices (Svn, P4, TFS, Mercurial, Git), but are not recommended. With subversion in particular, its “mergeinfo” properties design historically caused issues with reintegrations into the trunk. Indeed for the non-DVCS tools bringing back a merge on a branch, obscures the original commit enough for modern DVCS proponents to be quite vocal in their objections.
Java project using Maven specifically
Use of Maven in a Java project gives rise to some interesting problems. Maven projects have a pom.xml file in their root. That drives the additional choices you have to make given it contains the version number of the buildable/deployable thing within it. In a release cycle you might want to change it to 1.0-RC1 from 1.0-SNAPSHOT. Maven has a build in “release” command, that will make the changes to pom.xml in-situ on the trunk. The command even does incremental commits. The trouble is that it kinda needs a code-freeze, which TBD doesn’t require generally. This might drive an organization to using the “branch just before release” model, as it creates a naturally code-frozen place, that doesn’t change developer use of the trunk at all. Maven gets a lot of bad press, but many organizations use it well.