Paul Hammant's Blog: What is Your Branching Model?
Update: See the new resource site for Trunk-Based Development called, err, TrunkBasedDevelopment.com and make sure to tell your colleagues about it and this high-throughput branching model.
Note: At no point are we asking about local branching (on your local workstation with Git, etc). This is all about branching on the remote repository. That is if your company has one, and isn’t completely distributed, with no central repo.
Mainline
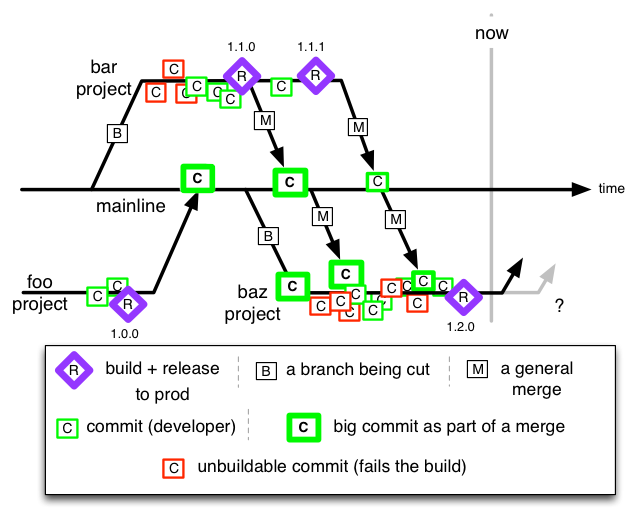
Teams develop on their own branches, and release from them. The then merge back to ‘mainline’ after the release. Many developers co-exist on one branch that can last for months, and that’s how major projects are separated. Some branches can be shorter in time than others. Sometimes one ‘in-flight’ branch receives interim merges from another in-flight one, despite the intention to merge from mainline exclusively when it’s been updated (after release).
IBM/Rational’s ClearCase really promoted this from 1998 through 2008. Nobody ever got fired for buying IBM.
Cascade
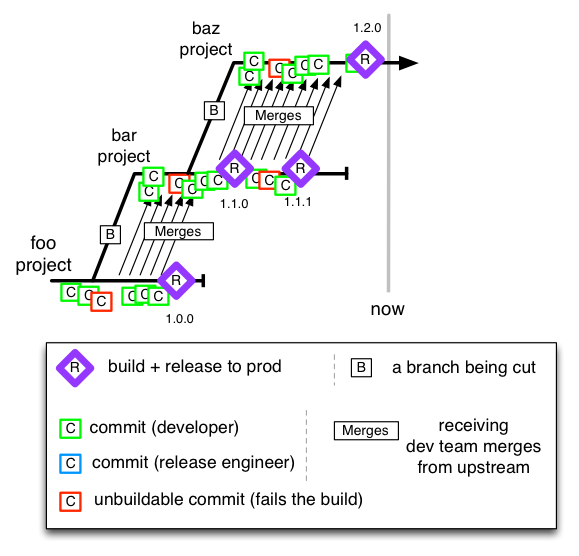
Project teams develops on their own branch and release from there when complete. Following releases (for separate projects on the same codebase) are on a branch from taken from the one before. The ‘downstream’ team merges as frequently as they can from the “upstream” branch. It’s a way of handling concurrent development of consecutive releases, but there’s a considerable cost of merge and an even bigger cost of un-merge (of you change the order of major releases).
I’ve only ever seen this once, so I don’t know how prevalent it is. I advised a change to trunk based development, and that paid off shortly after.
Trunk-Based Development
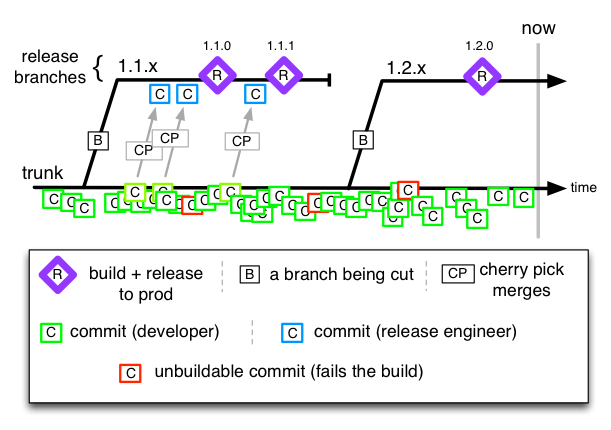
All project teams develop on a single trunk. Branches happen for releases only (only if a tag was not enough), with cherry-picks TO the release branch for defect-fixes. Teams probably use Feature Toggles, and Branch by Abstraction too in order to fit that concurrent development of consecutive releases goal.
If you didn’t know already I greatly favor this one in the enterprise.
I prefer that production defects are reproduced on the trunk, and merged to the release branch, but there are many that disagree.
Perforce from the middle 90’s and Subversion from 2001 promoted a trunk model, although neither preclude other branching models. Google have the world biggest Trunk-Based-Development setup, although some teams there are going to say they are closer to Continuous Deployment (below). Facebook are here too.
Short Lived Feature Branches
Allegedly short lived - there’s a risk of the Feature Branches morphing into the ‘Mainline’ prophesy (above).
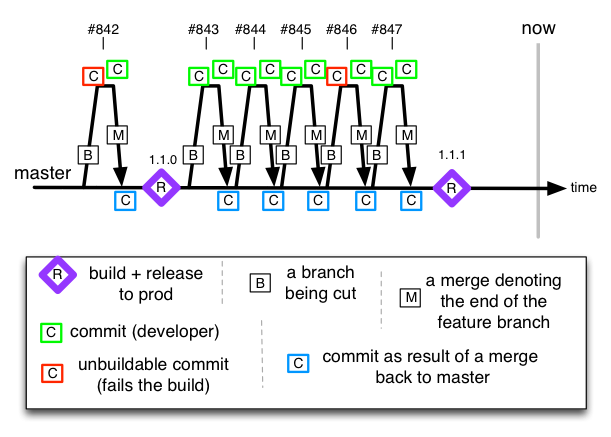
All developers make their own feature branches on the remote, work there, and merge back to master after a couple of days “tops”, when they have finished. They then delete the feature branch. This is not unlike doing the same practice on your local-workstation (local branches as Git promotes), but when they are pushed up the canonical repo, there’s a potential for sharing, and indeed help completing the feature. You could even hook up CI to those short-lived branches automatically to guard temporary the value they represent.
Continuous Deployment
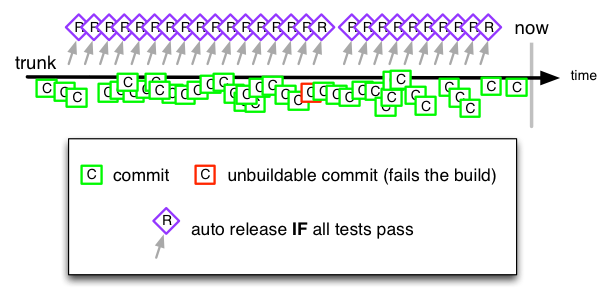
Commits can go all the way to production from one trunk/master, if the automated build says the commit was good. It’s the turbo-switch for TBD, where no humans can hold up a release by taking their sweet time testing it and giving a belated seal of approval. Github, Etsy, Netflix (and many more startups) are all here.
Subversion noise on branching
When Subversion came out it was suggested that “lightweight branching” was one of the benefits over CVS. When Git came out it was suggested that “lightweight branching” was the benefit over Subversion. Who was right? I think the Subversion branch-creation process is quite noisy - it marks every line as an add, when (versus the trunk) it was not like that. In the diagrams above, I’ve used C in a square to denote a commit, and made the size of the square the size of the commit (implies complexity/noise). Really for Subversion there’s a commit that’s sizable that comes with branch-creation and worth it’s own visualization, even in the TBD model that I prefer:
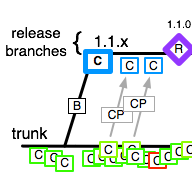
Git and Perforce (as you make a branch) don’t have that weight of commit. Here’s the filed issue - not sure whether the Subversion leads will agree.
More Notes
The Perforce people in their 1998 PDF “High-level Best Practices in Software Configuration Management”, presented that “trunk” and “mainline” were the same thing. They did now know then that Rational, around the same time, was going to forever cast Mainline as something else. They also don’t have this PDF on their site any more, which is a pity. You can still find it in Google, unless they go through a DMCA takedown exercise :-(