Paul Hammant's Blog:
Testability and Cost of Change
That ThoughtWorks consultants, with others, were at Google for a year and a half on a mission to help socialize better testing practice is now a matter of public record thanks to then team-mate Mike Bland. His 9699-word blog entry details a lot of Google inside-knowledge and experience from the “Test Mercenaries” mission as well as his participation with “Testing Grouplet” which existed long before and after the Test Mercenaries mission. “Design for Testability” their war-cry before the Mercenaries team was created, and will be I’m sure long after we’ve retired.
Some Context
Here’s a synopsis of the ‘cost of change curve’:
“Bugs are cheaper to find/resolve in a design stage, which is cheaper than finding them in development, which is cheaper than finding them in QA, which is cheaper than finding them in production”
It is an industry claim of course. It has been doing the rounds since Barry Boehm’s 1981 book Software Engineering Economics. Boehm’s logarithmic non-curve:
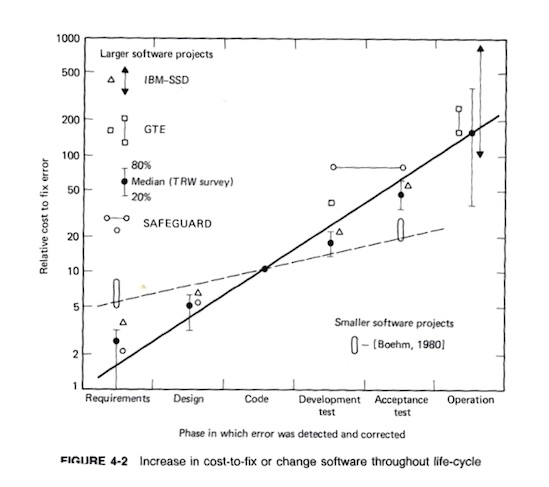
Perhaps even before that in 1976 in a IEEE magazine article also by Boehm. It is pertinent to traditional (waterfall) software development. Here is a simplified view:
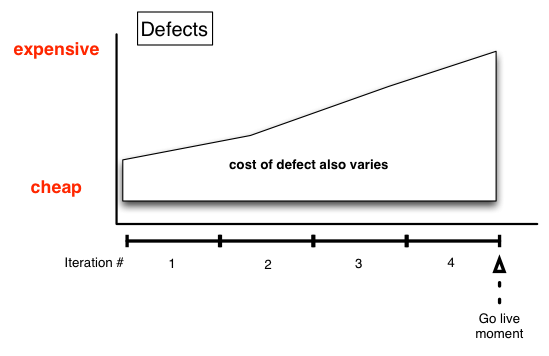
One debatable aspect of the above is whether this is equally true for defects and changes. Defects/bugs are implicit mistakes against an intended design. They range from tiny to large ones that have a negative financial impact. Those impacts could merely be the cost of remediating it and re-deployment if that’s applicable, or could include losing a fortune (say a trading platform buys stock instead of sells). Changes could be small again (UI tweaks at a rapid-prototyping stage) through to “whoops, we’ve hockey-sticked and Rexx is the wrong language for scale, everything needs to be rewritten from scratch’ (very big). In fact the line between perceived defect and change is sometimes fine-grained.
Design for Testabilty Fan Fiction
Back to the Google mission: I conjured up some dollar values in order to use ‘cost of change’ to motivate Google developers. I chose figures that are probably only applicable to Google, and dwelled on cost of defect rather than change in the absence of defect.
Indeed Google, by my reckoning, had an incredibly low cost-of-change engineering setup. They achieved this by having an incredible build infrastructure, a hard-core focus of development best practices, and a rabid code approval rule-set than meant that all devs became better all the time. In terms of tooling, hard-core refactoring was a reality, at least for the Java bits and pieces as Eclipse and Intellij were the two choices for IDE. Each of those IDEs had custom plugins to leverage what amount to a super-computer for compilation.
Anyway, here’s the line I used on occasion
“The bosses have done the analysis to determine that defects found in analysis/requirements/planning cost $1,000 to correct. Similarly bugs in development range to $10,000 if they are serious enough, up to $100,000 if found during formal QA and 1 to 10 million dollars if they become bugs in production that might require a rollback, crisis management, or law-suits / regulator fines.”
Of course, none of that had any basis in fact, and in no way came from management. I also have no evidence to suggest anyone was ultimately swayed at all, but it did focus attention for a conversation about the importance of Design for Testability.
Anyway, consider the diagram below:
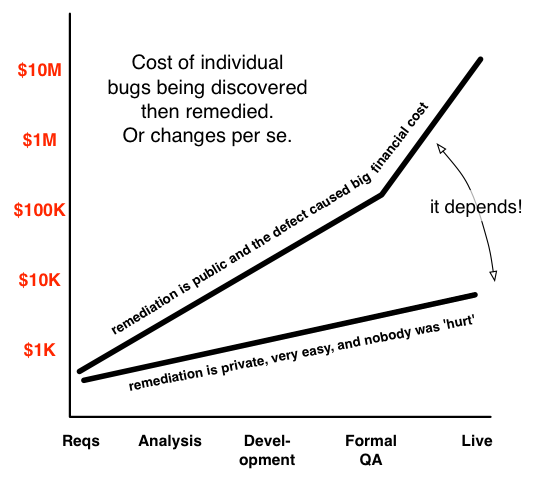
Google risks changes/defects close to that upper bounds. I guess investment banks could go 50x higher than that for the ‘in production’ discovery that bought a billion shares at market value, when it should have sold. If a costly defect is caught before you go live, then it’s not a regulator-fine-you, or clients-switch-to-competitor-or-take-you-to-court level of cost. Even without the fine/penalty the remediation costs can be large for bigger teams whose release schedules are turned on their head to create room to rework whatever is wrong. Smaller startups are going to be nearer the lower edge. Team size and inherent nimbleness aids them, as does the reality that many of their are not charging for their service. Cuil (the search engine) was an interesting ‘startup’ case, where the cost was ultimately huge. They may not have succeeded anyway, as ‘search’ is a crowded market. That said, startups can always plan to be acquired, and PowerSet showed (Microsoft bought it and turned it into Bing.com).
Mark Striebeck (The first Test-Mercenaries manager) in a 2009 speech, cited different figures:
They estimated that a bug found during TDD costs $5 to fix, which surges to $50 for tests during a full build and $500 during an integration test. It goes to $5000 during a system test. Fixing bugs earlier would save them an estimated $160M per year.
His were more likely the result of an exhaustive analysis, as opposed to mine which were made up (sorry again!). Brad Green (took over from Mark in the last quarter of our mission) hasn’t blogged/spoken on the Mercenaries mission, yet.
eXtreme Programming
Kent Beck’s eXtreme Programming (XP) claims that the cost of change can be closer to a flatline. This is the case as XP mandates ‘most stable’ code developed in a Test Driven Development (TDD) style. Also, perhaps, an IDE that’s an infallible facilitator of refactoring nirvana. You can make arbitrary changes using the refactoring tools and watch your code move around quickly without introducing defects. Our Mercenaries mission was to not flip every team we encountered to XP, just to draw on individual practices. Indeed, the flatter cost of change curve for XP is only for an “embrace change” vision of development. It is not for a ‘oh shit we’re giving ads away for free’ defect that’s still hugely costly. XP, and test-first with high test coverage, is about moving the defects leftwards though. Thus, the likelihood of worst-case scenario is reduced. Here are a couple of graphs (all in this page are drawn in OmniGraffle to outline a hypothesis) for change & defect (XP projects):
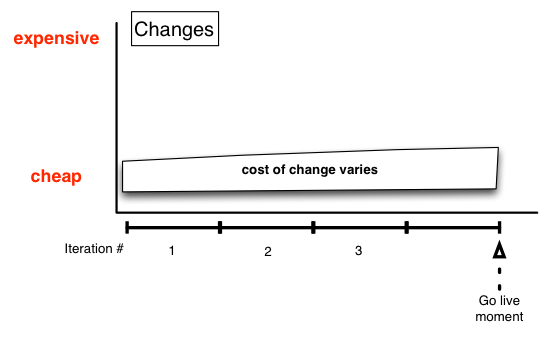
(A quick reminder, the above and below are for well factored code made via TDD)
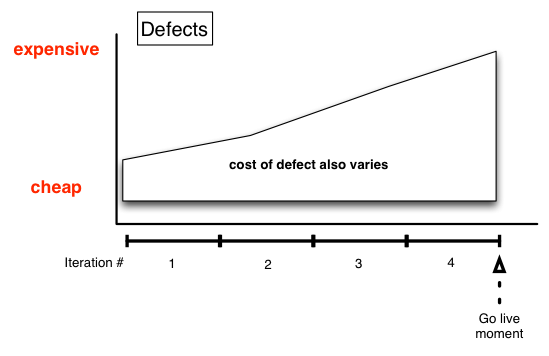
So our hypothetical project is four iterations before it goes live. It goes live at the moment of close of the last iteration. That isn’t very realistic, but makes for a simple graph. Say each iteration had a list of stories/items that were perfectly completed within it. Say twenty per iteration. The stories/item may have varied in duration, but we’ll consider that each transition through stages: The first was the business analyst talking to the customer (or product owner) about a INVEST-centric slice and writing it up. The next was development followed by QA, followed by a sign-off in the form of a desk-check, followed by a status update to “ready for production”, at which moment all activity around the story/item specifically ceases. Any subsequent work on this story/item is likely because a defect in it is discovered while working on another story/item. XP projects don’t plan for that, they plan for that not to happen.
What if all hundred items (4x 20) were plotted on a rough ‘start to finish’ timeline, with their stages synchronized, and we plotted the incidence of defect and the cost. That workflow timeline, with defect incidence may look something like this:
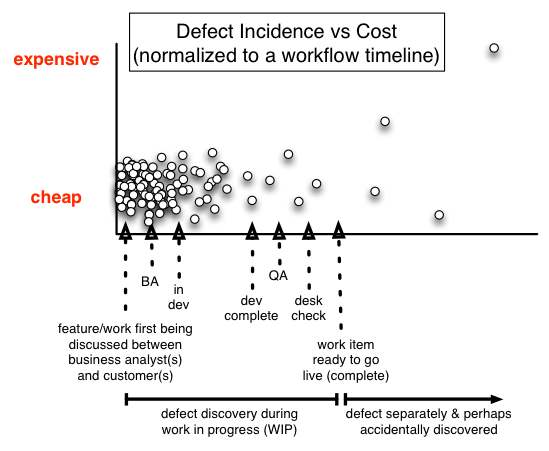
Hmm, I’m still not sure that’s right. Anyway, it shows a greater frequency towards the left (earlier) stages. Through enthusiasm for testing, and a number of facilitating techniques and tools, defects are found sooner, and consequentially not so costly.
Other Googly/ Test Mercenary things
Bubbles!
Miško Hevery with help from Jon Wolter, wrote an ActionScript app that showed the enthusiasm for testing for developers within a project team. Jon Wolter blogged about it after we rolled off, because Miško was up to his neck with the development of the revolutionary AngularJS.
Singletons
I’ve always been obsessed with the abolition of singletons (the design pattern) in enterprise application development, and in favor of Dependency Injection. I talked of the need for a “singleton detector” and one of Miško’s summer interns, David Rubel, coded it in a few days against Java bytecode. It uses ASM for the bytecode traversal. Some of the unfortunate naming might be my fault, and that is not for the first time.
Here is a screenshot made via Stephan Heiss’ tIDE project, which has integrated GSD to some degree. Screenshot from the project site:

Spending some time with yEd to find the optimal line-detanglement algorithm, printing this on a large format printer, and pinning it up is IMO a useful exercise towards testability.
I’ve wished for this in .Net recently :(
Obsession With Documentation
Google bosses created a culture of “write it down”. From what I understand that was as simple as declaring it so in the early days. Thus, and using their own technologies, Googlers documented the shit out of everything. Weekly progress reports (“snippets”), team machinations, initiatives, interest groups, trends, research, know-how, directions, and rationales were all recorded. This was also true of 20%-time activities. All of this was enthusiastically typed into collaborative documents, with news feeds attached. There was also an intent that documents were kept fresh, where appropriate. Also, the tables of contents and cross-references had to be pretty good as page-rank isn’t that great for a ‘closed’ system where new content is naturally more relevant than historical content. At least, the search-ability wasn’t that great at the end of 2008. Many users of corporate wikis will agree that search is the weakest attribute of their installation. If there was one single cultural change I’d make in ThoughtWorks it would be to replicate Google’s enthusiasm for “compounded knowledge”.
Selenium-Farm
Google’s Selenium-farm facility was huge boon to developer productivity. Jason Huggins was lured to Google from ThoughtWorks to join that team before the Mercenaries mission started. I finally got him to agree that my bit of Selenium (the your-preferred-language-steers-the-browser-over-TCP/IP bit) was more relevant than his (instructions-in-HTML-tables-steer-adjacent-Iframe)! Selenium2 (Simon Stewart also left ThoughtWorks to join Google) was starting to take over generally by the time I left. I’ll bet that’s complete by now. The selenium farm itself was very much virtualized, and there was nothing physical to see.
Trunk-Based Development
Google do “Trunk-Based Development” of course, using Perforce. That’s not been a secret for a while. A git front-end was released by the Perforce folks a couple of weeks ago, and they pre-announced it in a blog entry at the start of the year. Google, back then, had their own in-house version of the same, that some hard-core developers used to juggle local branches.
Do I miss Google?
A little I guess. Most of all I feared that Google would be the pinnacle of my tech career. It has not panned out that way. I have encountered other enterprises with tremendously inclusive corporate cultures. A national budget airline, for one. Most recently I finished up a Director of Engineering stint for an RBI subsidiary which was hugely educational (actually it was a schooling for me in such matters). So there’s always new challenges, and I’m better being the sum of all of my experiences.
Syndicated
Nov 14, 2012: This article was syndicated by DZone