Paul Hammant's Blog: NoSQL for storage AND relational for reporting
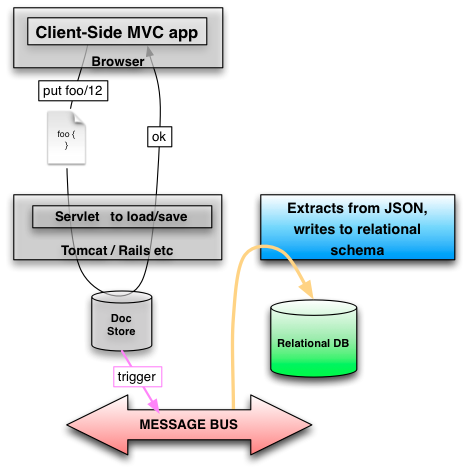
Given I think there is a shift afoot towards client-side MVC dealing in whole JSON documents up and down the wire, I’m wondering if there is also need for a technology to transparently create/maintain relational record sets for the pertinent document writes. Relational records are desirable as they would support easy SQL-using reporting tools. Tools like Crystal or Jasper Reports.
I’m not so much interested in the enhancements to SQL that allow for JSON fragments in queries. Nor am I interested the custom search engine solutions like elasticsearch that allow for sophisticated querying of an index. I’m looking for something that does secondary writes to a normal relational schema (whether defined or automatically generated), in such a way that Crystal or Jasper reports (or equivalent) could easily consume records for reporting. The resulting schema (aside from the cost of the secondary writes), would be optimized for queries.
Martin Fowler, as ever, sets the foundation for what I’m wanting with a bliki entry ReportingDatabase
A worked example
Here’s JSON fragment similar to the first one on: http://en.wikipedia.org/wiki/JSON
{
"id" : 101,
"firstName": "John",
"lastName" : "Smith",
"age" : 25,
"address" :
{
"streetAddress": "21 2nd Street",
"city" : "New York",
"state" : "NY",
"postalCode" : "10021"
},
"phoneNumber":
[
{
"type" : "home",
"number": "212 555-1234"
},
{
"type" : "fax",
"number": "646 555-4567"
}
]
}
If that resource were overwritten in a NoSQL database, then it would be one I/O. A trigger could pick that write up and, in Postgres at least, could handle the economic updates as well as the deletes/writes as applicable into a relational schema. In this case that would be four writes (hopefully to a separate database/server to the document store):
Person Table
| id | firstName | lastName | age |
|---|---|---|---|
| 101 | John | Smith | 25 |
PersonAddress Table
| id | streetAddress | city | state | postalCode |
|---|---|---|---|---|
| 101 | 21 2nd Street | New York | NY | 10021 |
PersonPhoneNumber Table
| id | ix | type | number |
|---|---|---|---|
| 101 | 0 | home | 212 555-1234 |
| 101 | 1 | fax | 646 555-4567 |
Extracting relational fields from JSON declaratively.
Ideally, there would be a declarative XPATH-like language that would allow us to tersely declare the sections of a JSON document we would want to explode into rows in a relational schema. Two alternates exist already - JAQL or JsonPath, but we’d want to use them in a way that would batch process documents into cohesive SQL statements:
{
"tables":
[
{
"name" : "Person",
"key": "id",
"fields": "firstName, lastName, age"
},
{
"name" : "PersonAddress",
"key": "id",
"fields": "address.streetAddress, address.city, address.state, address.postalCode"
},
{
"name" : "PersonPhoneNumber",
"key": "id, phoneNumber.@index as ix",
"fields": "phoneNumber[ix].type, phoneNumber[ix].number"
}
]
}
Whether DDL could be automatically extracted to issue the correct CREATE TABLE statements is debatable. It’s also not clear whether JSON will be a successful notation for extracting relational data from JSON documents.
PUT versus POST
Web apps are classically constructed from GET and POST applications. Here is a timeline of web technologies in two blog entries - 1993, 2000, 2006 and its follow-up 2012, lastly one extolling the virtues of document is the single source of truth. In the second and third I talk about the potential for PUT as a mechanism for writing back documents that were ‘worked on’ in a page. In relation to today’s blog entry, the PUT of the whole document all the way back to the database is powerful because it facilitates a trigger on the old and the new document in one operation. You may be driven to POST because of a larger document size, and have to do additional processing in your persistence tier to make sense of that in a document store, but the consequential conversion to a relational form would still be possible.
Of course, whether PUT or POST, JSON docs or fragments would still need re-validating on the server-side as well as auth/audit/access control.
It’s important to note that many esteemed ThoughtWorks colleagues counsel against PUT and for POST to do discrete updates to a backend document.
Blast from the past: Oracle’s Intermedia.
Eleven years ago Oracle had a technology Intermedia that would (amongst other things) take a write of XML to a clob and write out additional records to related tables to allow direct indexing of XML attributes/elements. They don’t so much talk of it any more. I can’t remember whether that was done in real-time or not, but it feels like it was in the same space as what I’m wanting.
MicroSoft’s SQL Server Analysis Services
Like Oracle’s InterMedia, Microsoft have a technology SQL Server Analysis Services. Unlike Intermedia, it is most definitely current.
Amongst many other OLAP things, it explodes XML clobs into eminently searchable cubes. Using this MAS (?) piece, it is easy to make cubes for various sets of data, and from that perform easy reporting very much offline. In the end though, it is not quite what I’m looking for.
Follow ups.
Nic Ferrier for one is itching to write something more technical for the NoSql to relational idea. I’ll link to it when he finishes it.
Jun 13, 2012: There’s also need to a full rebuild job that drops the all rows in the relation schema and rebuilds from scratch (on demand). One knows, with these things that divergence because of events is inevitable.
Feb 5, 2013: MoSQL replicates MongoDB into Postgres for reporting
Syndicated
Jun 12, 2012: This article was syndicated by DZone