Paul Hammant's Blog: Binary Diffing for Increased Release Confidence
This blog entry is about enterprise release teams regularly declaring a
code freeze in the run up to go live for a release, and why that need
not be so mechanical. Lets assume an intended trunk model like so:
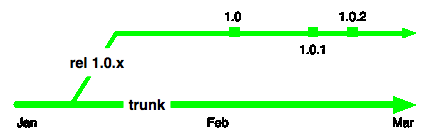
We will also assume you've read my Branch by Abstraction blog entry and Martin's FeatureBranches, and FeatureToggles. You may even have read Jez's Continuous Delivery book.
Now for major releases, of course you're going to stabilize somehow before you push a release out. But the question is what techniques to you use to effect that. There's a classic code-freeze way, but is there a a way of using tools and techniques to gain assurance without code-freeze per se ?
Large enterprise periodically pushing releases to production where the binary comprises a lot of different files, sometimes to a cautious routine to prevent mistakes. There are many reasons why they do this but lets mull just one: mistakes happen and releases get botched when last minute changes destabilize something that has been tested. Therefor a prudent manager instigates a practice of code-freeze. A team would immediately observe that releases get spaced out like so:
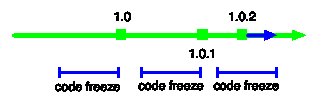
Other than slowing down the pace pace of delivery to production, the problem for real life releasing is that you may find an important regression that could be fixed inside that code freeze window. What to do then? Delay the release further - specifically fix the defect then restart the code-freeze window?
Most likely that release had a release candidate tested in a staging environment was otherwise good to go before someone (or some automated suite) found the regression:
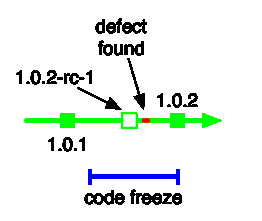
Lets use numbers now. 1.0.2-rc-1 was nearly good to go. There was ton of time, and lots of people involved in deploying it an certifying it. Then a the regression/defect was found, seemingly invalidating that work. According to code-freeze thinking the release should either be delayed, or there should be a follow up release (say 1.0.2.1) to address the defect. The fact that the defect would be fixed on trunk by an Agile team without delay and could be cherry-picked to the branch easily, is irrelevant to the thinking behind code-freezes.
Software Engineers are going to point at the source control system to help us gain assurances. They'll say that you can compare the 1.0.2-rc-1 tag to the 1.0.x branch to gain assurances about the single cherry-picked bug-fix being un-risky, and not requiring the full release certification that happens inside the code freeze window. Managers are just not going gain comforts from that claim, even if supported by copious amounts of generated information.
Not everything in a release is held under source control though. Or if it is, not everything is in the same convenient directory.
We've heard of cases of enterprises putting a single extracted Java class ahead of the other jars in a release, as a way of 'safely' patching a release's binaries after the event.
What if we could diff the binaries? What if we could present the data from such reports to managers to add weight to the argument that nothing other than the cherry-picked bug fix has change between 1.0.2-rc-1 and the 1.0.x branch (hypothetical 1.0.2-rc-2)
JayWalker is binary diffing tool for enterprise Java solutions. It was written in Java in 2005 specifically for this situation (and may not run on more recent Java releases). Java is a special case because Sun (in a moment of 1990's insanity) hit the turbo switch on the successful 'JAR' format for containing class files, and made 'WAR' files (that amongst other things) could contain JAR files and 'EAR' files that could (amongst other things) contain WAR files. All were zip format, which alleviates the crime only slightly. This makes for a massively opaque binary for a release.
JayWalker unzips recursively and compares the file content and names (dates of files within zips are always going to change so are ignored). The report it gives has details of new files (classes, html, etc), deleted files, and changed files. It is blind to the type of file being compared, meaning it picks up changes to configuration files too (.properties, .xml, etc). It also drills into third party stuff in the distribution in the same way.
Armed with the proof that single class changed, you might be able to persuade management that we're still good to go, and that code-freeze now means use binary release diffing for cast-iron assurances.
This must be about 30 lines of Python right? Diffing Zips within Zips within Zips must be easy in a dynamic language that's friendlier to files and file operations. Can someone get to it please? Something that's less tied to Java binary releases than JayWalker ?
Monday, April 18, 2011
Update: A functional language might be better still.
Update2: (Tues, April 19, 2011): Blake Brezeale tells me off http://code.activestate.com/recipes/577620-jardiff/ which fits the spec.
We will also assume you've read my Branch by Abstraction blog entry and Martin's FeatureBranches, and FeatureToggles. You may even have read Jez's Continuous Delivery book.
Now for major releases, of course you're going to stabilize somehow before you push a release out. But the question is what techniques to you use to effect that. There's a classic code-freeze way, but is there a a way of using tools and techniques to gain assurance without code-freeze per se ?
Enterprise Release Caution
Large enterprise periodically pushing releases to production where the binary comprises a lot of different files, sometimes to a cautious routine to prevent mistakes. There are many reasons why they do this but lets mull just one: mistakes happen and releases get botched when last minute changes destabilize something that has been tested. Therefor a prudent manager instigates a practice of code-freeze. A team would immediately observe that releases get spaced out like so:
Other than slowing down the pace pace of delivery to production, the problem for real life releasing is that you may find an important regression that could be fixed inside that code freeze window. What to do then? Delay the release further - specifically fix the defect then restart the code-freeze window?
Most likely that release had a release candidate tested in a staging environment was otherwise good to go before someone (or some automated suite) found the regression:
Lets use numbers now. 1.0.2-rc-1 was nearly good to go. There was ton of time, and lots of people involved in deploying it an certifying it. Then a the regression/defect was found, seemingly invalidating that work. According to code-freeze thinking the release should either be delayed, or there should be a follow up release (say 1.0.2.1) to address the defect. The fact that the defect would be fixed on trunk by an Agile team without delay and could be cherry-picked to the branch easily, is irrelevant to the thinking behind code-freezes.
Software Engineers are going to point at the source control system to help us gain assurances. They'll say that you can compare the 1.0.2-rc-1 tag to the 1.0.x branch to gain assurances about the single cherry-picked bug-fix being un-risky, and not requiring the full release certification that happens inside the code freeze window. Managers are just not going gain comforts from that claim, even if supported by copious amounts of generated information.
Not everything in a release is held under source control though. Or if it is, not everything is in the same convenient directory.
We've heard of cases of enterprises putting a single extracted Java class ahead of the other jars in a release, as a way of 'safely' patching a release's binaries after the event.
What if we could diff the binaries? What if we could present the data from such reports to managers to add weight to the argument that nothing other than the cherry-picked bug fix has change between 1.0.2-rc-1 and the 1.0.x branch (hypothetical 1.0.2-rc-2)
JayWalker
JayWalker is binary diffing tool for enterprise Java solutions. It was written in Java in 2005 specifically for this situation (and may not run on more recent Java releases). Java is a special case because Sun (in a moment of 1990's insanity) hit the turbo switch on the successful 'JAR' format for containing class files, and made 'WAR' files (that amongst other things) could contain JAR files and 'EAR' files that could (amongst other things) contain WAR files. All were zip format, which alleviates the crime only slightly. This makes for a massively opaque binary for a release.
JayWalker unzips recursively and compares the file content and names (dates of files within zips are always going to change so are ignored). The report it gives has details of new files (classes, html, etc), deleted files, and changed files. It is blind to the type of file being compared, meaning it picks up changes to configuration files too (.properties, .xml, etc). It also drills into third party stuff in the distribution in the same way.
Armed with the proof that single class changed, you might be able to persuade management that we're still good to go, and that code-freeze now means use binary release diffing for cast-iron assurances.
A modernized Python/Ruby successor
This must be about 30 lines of Python right? Diffing Zips within Zips within Zips must be easy in a dynamic language that's friendlier to files and file operations. Can someone get to it please? Something that's less tied to Java binary releases than JayWalker ?
Monday, April 18, 2011
Update: A functional language might be better still.
Update2: (Tues, April 19, 2011): Blake Brezeale tells me off http://code.activestate.com/recipes/577620-jardiff/ which fits the spec.