Paul Hammant's Blog: Provisioning, Deployment and Application Config Cycles
In my opinion:
- provisioning should be via “Infrastructure as Code”
- deployment of application binaries is as it’s conventionally understood today
- application config should be “Configuration as Code”
Here’s a handy diagram of all that, for a single hypothetical environment:
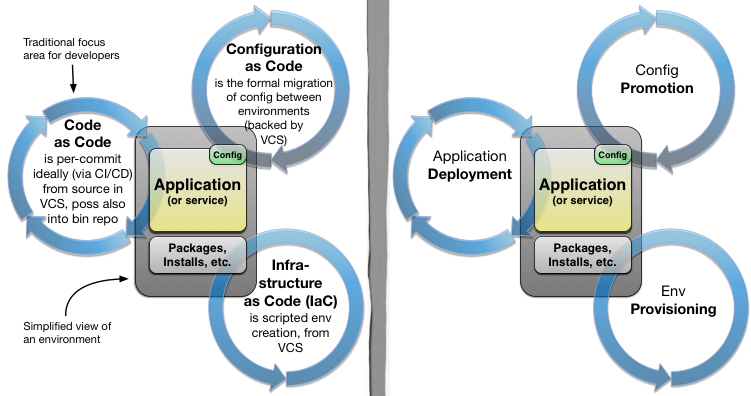
Before I go into detail, it is important to know rationale behind the pipeline thinking of Continuous Delivery.
Infrastructure as Code
For non-live environments you should maintain blueprint scripts under source control that can create or recreate whole environments from scratch. That should include allocations of VMs, installation of packages needed (Apache, Tomcat, MySql, reverse proxies, load balancers) that doesn’t come with the chosen base OS on a vanilla VM. Everything that’s implied by the word “platform” perhaps. You’d also bake in intra-VM connectedness here - firewalls, DNS. The configuration of packages would be here too. e.g. Apache’s httpd.conf.
For production, you’d have blueprint scripts too, but in reality only ever make changes in a delta-esque following CD best-practices. At least once you’re live already.
The source-control repo in question would only contain Infra-structure as Code. Perhaps one branch per environment, perhaps not. Templating could figure too:
my_provision QA3 --from templates/one_vm_fewest_processes.yaml
Sometimes enterprise want a self-service portal for provisioning. I’m not sure that’s needed, when a command-line tool is just as good functionally.
Though Terraform is newer and very cool, colleagues Jefferson Girao, David McHoull and Deluan Quintao did a great blueprint implementation using Ansible nine months ago.
From that project’s Github repo, a sample YAML blueprint for a “pet store” application (two VMs):
# This playbook deploys the whole application stack in this site.
- name: apply common configuration to all nodes
hosts: all
roles:
- common
- name: configure and deploy the web-servers and application code
hosts:
- www.petshop.example.com
roles:
- ruby19
- passenger
- nginx
- name: deploy MySQL and configure the databases
hosts:
- db.petshop.example.com
roles:
- mysql
Application Binary Deployments
You might have environments Jenkins01 through Jenkins10 which Jenkins-CI deploys into per-commit just before it enters ‘full stack’ Selenium phases of the build pipeline. Humans don’t go into those. Some teams in a Continuous Integration loop, may want to provision a fresh temporary environments per deployment and Selenium testing phase, but it is my opinion that you don’t need to - they can be reused in this context.
Regular deployments into QA1, QA2 or UAT, would be from a button click in Jenkins. At least, after choice of binary (say rel-1.1-build-12345) and environment. In addition to the simple app - XXX application version N.n into YYY environment - having a command-line equivalent would please the more technical members of a dev team. Some companies are going to want a portal for deployments, instead of the cheap Jenkins implementation. The fewest choices in that portal - “are you authorized to (re)deploy?”, “which version of which app?”, and “into where?” would be the minimal controls on the deploy portal.
You could have a CD style auto-deployment into a QA environment. Only if redeploy doesn’t temporarily make the environment usable. If instability on deployment does happen, then maybe redeployments only happen at agreed times. CD, for the most advanced teams, means deploy into production of course.
Application binaries can only happen to environments that have been provisioned correctly. That means that the Infrastructure as Code stuff has happened already, if that wasn’t obvious. If environment provisioning and application binary deployments have happened without the config (see below), then the environment is NOT usable at this stage.
Which bits of this are under source-control?
Alongside regular build scripts, I would want to see the full CI pipeline definition. CruiseControl used to do that , and I’d prefer it if the likes of Jenkins do so too (as I once put to Kohsuke Kawaguchi - Jenkins’ creator). The products of builds - the application binaries themselves? Many enterprises should be putting the binaries in a tamper-proof repository (not source-control) and pulling them from there for deployment. Some high-bar CD teams are not going to bother with that. Instead they’d deploy at the end of the build/test cycle and discard the binaries.
Configuration as Code
Problem: You want this application configuration to remain in an environment even after redeployments of binaries. What’s the best way to do this?
An installed application can receive configuration as it changes orthogonally. This could be binary toggles if you’re doing dark deployments or can turn off non-critical parts of the app to boost performance (or resist an attack). It could also be more considered settings (JSON):
"first_line_support": {
"cell": "415 867 5309",
"name": "Jenny"
}
If you were doing poor-mans load balancing down a stack, you could also encode endpoint info in this category of config (JSON):
"zipcode_service": [
{
"name": "zipcodez.qa2.sandwichcorp.com",
"port": 33452,
"state": "active"
}, {
"name": "zipcodez02.qa2.sandwichcorp.com",
"port": 11233,
"state": "active"
}, {
"name": "zipcodez.qa2.sandwichcorp.com",
"port": 44444,
"state": "suspended"
}
]
You want this stuff under source control (separate repo again). The concept of environments implies application configuration variance as well as binary variance. As such, you’ll want to use one branches per environment (maybe not all those JenkinsXX ones). This will allow you to merge keys and/or values between environments if needs be. Highly mature CD teams will make new keys act benevolently on a system that doesn’t understand them, so they can go live ahead of schedule. You could promote changes as a set, or individually (cherry-pick).
Note: Zookeeper and Etcd solve the same problem, but I’m not going to feel comfortable unless source-control is the underlying system, and round-trip.
What else does App config need?
Editing config via an admin app is definitely needed. Logan McGrath coded a whole config-app before for me: SCM-Backed Application Configuration With Perforce and App-Config-App in Action (videos of use) and Promoting Changes With App-Config-App . Not only do you want an admin/editing app, you want round-trip editing to work, such that a hard-core engineer could checkout a branch of config on the command line, edit in Vim, and commit/push back to trigger a re-publication of config.
What else could App Config be?
Partner and third-party interop configuration whether that is one or two partners, or tens of thousands. Professional Services teams may be maintaining each, and wish for go-live cycles that are decoupled from binary releases, and that is exactly what Configuration as Code facilitates.
Content Management also springs to mind. Source-Control branches could be places that allow the the coordination of “content” changes, and where they approved somehow, before the final promotion (merge) to production. Diffing helps too, both during a coordinated rework of the content, and at the end before the promotion to live (as a last validation stage).
Contrasting the three life cycles.
Infra as Code and App Binary Deployments are certainly part of a conventional pipeline view. The Config as Code lifecycle isn’t though. It is orthogonal to that, but vital for application consistency.
The first two are baked into source-control by developers and devops experts. Config as Code is part of a more subtle human-centric management towards production readiness. Many non-developers are going to be involved in getting the config right. Maybe they will do that in the web application built to maintain the config (we used AngularJS to cheaply realize the necessary validations for the proof of concept Logan an I built). Source-Control gives you safety though - track what’s changed, when it changed, who changed it, and whether that change war right. Indeed (back on the command line, have some hard-core tools to revert select changes).
Further reading
Of course I’m rehashing prior thoughts and pics: Refer Application Architecture in the CD Era for Pro-Services teams and various from my blog category Configuration as Code.
Colleague Kief Morris (who also helped me get my message right in this article) posted a foundational Automated Server Management Lifecycle article many years ago.