Paul Hammant's Blog: Browser Downloads Suck
Generally sucks, I mean. The ‘download’ facility of web browsers generally sucks, where is you click the same item in a page to download, you get several copies in your downloads folder:
Downloads/
exciting-whitepaper.pdf
exciting-whitepaper(1).pdf
exciting-whitepaper(2).pdf
exciting-whitepaper(3).pdf
They stay there forever. The browser doesn’t manage them after littering the downloads folder with them.
Secondly, you are allowed to choose a default location. By Default that is ‘Downloads’ in the user’s home folder (‘~/Downloads’ henceforth). All browsers allow you to choose somewhere else, when you initiate a download, and some browsers remember that choice.
Examples of the problem
Pay-slips (pay statements) from ADP.
ADP is a B2B company doing (amongst other things) payroll for employers. They pioneered their field, and have transitioned smoothly into the web age, but their portal app for employees feels quite old. Here is a sample of a pay statement that they hold online for you. You can download them at your leisure, but it is time consuming, and they all get downloaded to your downloads folder as iPayStatementsServ.pdf (with perhaps a ‘(1)’ suffix if that file name already exists). The ADP app could incorporate the year, month, and other key data in the file name but it does not. That would allow me to batch download them, before filing them somewhere.
What I’d rather do is download them as a hierarchical file. Using their sample statement, I’d like that to be stored as ~/Documents/adp_paystatements/2008/07_25_paystatement_126543.pdf. Using current web technologies, ADP could incorporate some of the key information into the file name, but they couldn’t do anything beyond that. That I want ~/Documents/adp_paystatements/2013 for last year’s pay slips, and ~/Documents/adp_paystatements/2014 for this year’s ones is a matter for me and my web browser only. That default/last location thing isn’t good enough.
Content Management Systems (incl. Sharepoint)
CMSes including Sharepoint incrementally fail when you want to transition from viewing to editing of documents. When using it in a business setting, you could end up with a downloads folder full of multiple versions of the same file, and an increased risk of distributing or working on something out of date.
Because of the problems of download, and perhaps that you can’t assume MS Word is installed on all client computers, many of these technologies have in-page editing technologies (mostly Javascript these days). They also feel a bit second class. Perhaps integration for the sake of editing is a separate issue to downloads one specifically, but the same solutions for both could help fat-client editing of on-line resources in a way that doesn’t litter a ~/Downloads folder.
HTML 5’s download attribute
There is a “download attribute” for use with Anchors, that for the pay-statement example would allow:
<!-- current page is http://ipay.adp.com/paystatements -->
<tr>
<th>
Pay Date
</th>
<th>
Check No.
</th>
</tr>
<tr>
<td>
<a href="iPayStatementsServ.pdf?126543"
download="adp_2008_07_25_paystatement_126543.pdf">07/25/2008</a>
</td>
<td>
126543
</td>
</tr>
It’s no good with directories though and the following replaces the slashes with dashes, and totally ignores the directory organization:
<!-- current page is http://ipay.adp.com/paystatements -->
<tr>
<th>
Pay Date
</th>
<th>
Check No.
</th>
</tr>
<tr>
<td>
<a href="iPayStatementsServ.pdf?126543"
download="adp/2008/07_25_paystatement_126543.pdf">07/25/2008</a>
</td>
<td>
126543
</td>
</tr>
Try it for yourself on http://html5-demos.appspot.com/static/a.download.html. After clicking the “create file” button (1), inspect the element and add an implied directory (2) to the download attribute’s value. Then click the download link (3), and observe:
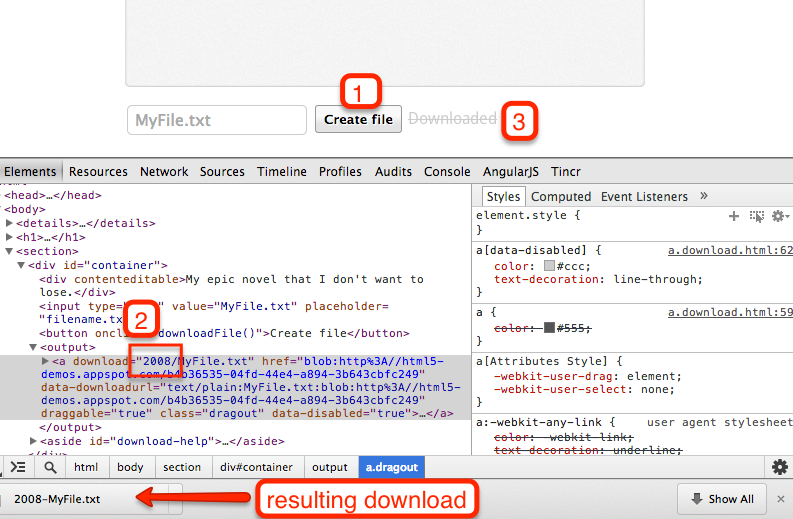
Ignoring that last, the download attribute suggests to the browser a fuller form for the file name that includes some director info, but not all. I myself want to place that in ~/Documents/personal/finance/pay/ the browser is going to have trouble remember where the persistent root directory is for that. Sure I could choose that in the first use of save-as, but should the browser remember that for all the downloadables from adp.com? I think not; I want my W2 (end of tax year summary) downloads to go elsewhere. More context is needed somehow.
Hazel
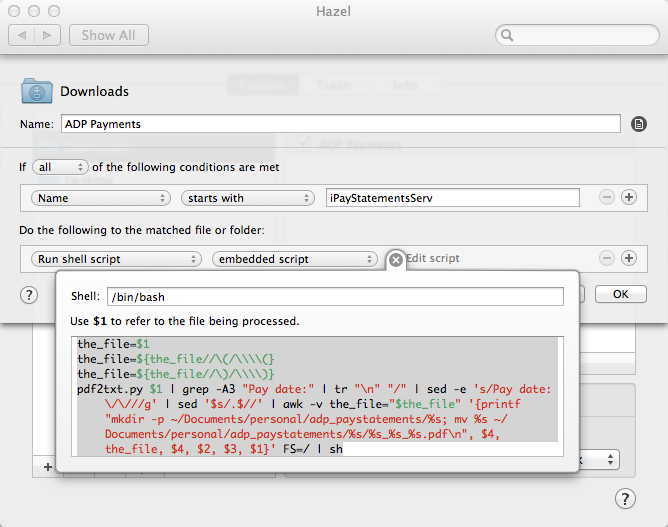
Because I can’t wait for the world to modernize to a version of HTML after 5.0, or even get the standards committee to agree to changes, I coded a script for Hazel (an automation tool for the Mac). It is some bash/sed/awk fu. I’ve also installed a Python utility called PDF Miner. Here’s the resulting script:
the_file=$1
the_file=${the_file//\(/\\\\(}
the_file=${the_file//\)/\\\\)}
pdf2txt.py $1 | grep -A3 "Pay date:" | tr "\n" "/" | sed -e 's/Pay date:\/\///g' | sed '$s/.$//' | awk -v the_file="$the_file" '{printf "mkdir -p ~/Documents/personal/adp_paystatements/%s; mv %s ~/Documents/personal/adp_paystatements/%s/%s_%s_%s.pdf\n", $4, the_file, $4, $2, $3, $1}' FS=/ | sh
It spots that iPayStatementsServ.pdf was dropped into ~/Downloads, pulls details out of the PDF and then files it permanently in the folder I use for my finances. If I happen to do the same item twice, it’ll simply overwrite it.
Here is the configuration in Hazel:
Browsers implementations could have a similar feature: On-Download scripts native to the OS in question. Post-processing for downloaded files :)
One more thing
Downloading of more than one file at a time sucks too. I mean initiating a download and having a series of files come down in one go.
Similarly downloading a zip file sucks. Should it not be auto-unzipped or not?. If it is, should that all be in a folder that shares the name of the zip? What should the time-stamps be on that so I can find it/them when I step into my ~/Downloads folder?
These too seem fixable via standards/attrs in HTML.