Paul Hammant's Blog: Legacy Application Strangulation : Case Studies
Strangler Applications
Martin Fowler wrote an article titled “Strangler Application” in mid 2004 (and “Strangler Fig Application” from early 2019).
Strangulation of a legacy or undesirable solution is a safe way to phase one thing out for something better, cheaper, or more expandable. You make something new that obsoletes a small percentage of something old, and put them live together. You do some more work in the same style, and go live again (rinse, repeat). Here’s a view of that (for web-apps):
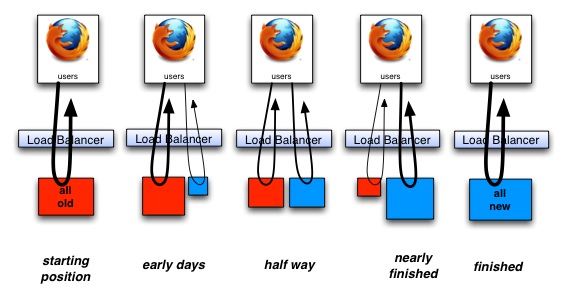
You could migrate all functionality from an old technology solution to new one in a series of releases that focused on nothing else. Some companies will do that as there is a lot of sense to getting your house in order before doing anything else. However people outside the developer team may see that as a non-productive period, that could lengthen at any time, if it were asked for at all. People paying for that will notice, and may object. I mean execs, the board, or shareholders looking at the balance sheet.
Better would be to weave in new functionality at the same time as doing the strangulation. This is easier to justify from a Capex point of view, but you have to be sure to not turn the effort into a big bang, or checkbook holders will object again if they are not seeing results. Moreover, any methodical plan can be paused after any release to re-prioritize how to spend money. A big-bang approach just increases in risk, where write-off of effort spent is the consequence of any significant pause.
Case Studies
An Airline’s Booking App
The profitable airline in question was quick to move into the web as mechanism for generating ticket sales. We’re talking mid-90’s here. That was a C++ app (NSAPI plugins).
In 2008, the C++ stack, though stable and performant, was a platform that was unable to be used as a starting point for ambitious site/app expansion plans. That and it was not so easy to recruit developers to work on it compared to the modern language.
Java, Spring and all that, is what the client went to, but any of the competing modern technologies would have been the same. The reason for citing this case is that the C++ stack co-existed at the same time in production as the new one. A load balancer routed requests to one or the other, with URL being the easy divider of functionality. The two apps agreed on the concept of a session, and indeed shared a session store, so could to a great degree redirect back and forth for a cohesive customer experience. That in itself was not so trivial, but worked well once the “backwards compatible” aspects had been perfected.
The initial proof of concept was by a couple of then ThoughtWorkers (Kent Spillner and Jessica Austin), and centered on a scraper solution re-using the live website for a wholly new experience in new technologies (see pretotyping below). After that a multi-year phased migration plan was instigated taking whole aspects of the old app to the new one. A number of consultancies were involved in this plan and execution (Thoughtworks was just one). Development was concurrently performed in a number of cities and time zones, and was about 100 people with commit rights at peak.
The first strangler deployments went live in 2009, and thence every six to eight weeks (although the size of each release would vary). The final pieces of the strangulation were complete in 2011. Every major release in that span took out part of the previous stack. Enhancements to functionality, once migrated from old to new, was well funded.
My biggest personal contribution was the advocacy for (and a hand in the implementation of) a single trunk for all work to happen in (hedging on the order of releases, and toggles to facilitate that can’t be beaten).
Trading Company’s blotter
Then-colleague Chris Stevenson, and Agile industry friend Andy Pols wrote a white paper for the XP 2004 conference. This paper was cited in Martin’s original article.
The “InkBlot” project (that’s not the real project name, but close) they wrote about, was at the same client I was at. I was not involved, but could see and hear their progress each week, as they were co-located with my dev team as part of a “programme of change” for the IT department of an energy trader (who can’t be named) which often has annual revenues with nine zeros.
In the team was Joe Walnes, Nick Pomfret, Ben Hogan, and Trevor Gordon as extremely sharp-minded senior developers, and Martin Gill as a super-calm project manager. Only Martin, Joe and Chris were ThoughtWorks staff, the others were freelancers in the local scene. Their Business Analyst (Gavin Smith) looked the part, as I recall - complete with pin-stripe suit.
Their starting position was a legacy PowerBuilder application over a Sybase database that was in heavy use by the client’s top traders. Trade blotters (no wikipedia page surprisingly) are widely used in larger trading organizations, but they are really “only” a front end to a larger data set of in-progress trades. Anyway, there was data and front end for this app already, but modernization was the agenda, and Java+Swing was the chosen technology. Because this wasn’t a web-application, the reverse proxy trick could not be used to make it appear to be one application during the phased migration.
InkBlot was a project that moved functionality from the old system to the new system in phases. The old app remained running, and used in production, until the new app has obsoleted it completely. Until that time, both are used in tandem. Thus is the strangulation aspect. Previously the client had thought for a long time about a rewrite, but the challenge was too large to yield the desired outcome, so methodical strangulation was easy for the client to commission. After that, the team was self-directed towards the technical solution.
Joe remembers InkBlot like so:
- A view onto the old database (not a platform in itself), that ..
- Served to have functionality incrementally moved from legacy to new technologies and capabilities, with ..
- Initially duplicated functionality and a deliberate choice of read-only mode, to make it a benign installation (a hedge against ‘dislike’), allowing ..
- Older PowerBuilder code to be strangled slowly and safely.
Joe’s favorite bit of the paper (I agree):
“We never told the users that they must use the new system. Nor did we remove access to the old system. We relied on making the system so compelling that there was no reason to use the old. This also meant that we stayed focused on the users real requirements”
The technology they settled on was a well-factored Swing app. It went as far as to offer Dynamic Data Exchange (DDE) into the the trader’s Excel spreadsheet (if they had it open). As mentioned above, initial releases were read-only, and the traders at some points were getting a new version daily.
Martin remembers the codebase being rewritten three or so times. For that high-achieving team, rewrite didn’t mean “stop delivering new functionality”, it means that the Test Driven Development (TDD) codebase allowed for casual redesign and tactical re-implementation so safely, that there was no reason why the team should not do it in parallel with planned functionality. This, of course, was a stream of lots of little commits into a shared trunk. There were times during the project when the app was deployed to live daily!
In terms of Agile, the team was doing eXtreme Programming throughout with very short iterations (three days or so). Stories were very small, and sign up for new ones was as they were finished, and fairly informal. Many aspects of their way could be said to be Lean, which had not quite taken root in the Agile industry back then. The emphasis of the white paper that came out of the project was the Agile achievements.
Multi-tenant rail-passenger booking app
This was a web application originally written in Visual Basic 6, and migrating to a .NET solution via strangulation (2008-2011). It ultimately settling on ASP.NET, and took a couple of years to complete that portion, while simultaneously developing appropriate new functionality. It went live many times in that period (part old, part new), with a six-week release cycle at peak. After the old app UI was completed replaced (and turned off), development and releases continued so but with a pure enhancement schedule.
The fairly large team switched to a Trunk-Based-Development branching model earlier on (complete with Branch by Abstraction and Feature Toggles). The allowed defects to be found soonest (refer the cost of change curve).
In terms of technical challenges, as well as moving to a decomposed Model-View-Controller architecture, the business was keen to see Web 2.0 behaviors in the app, and much of the story backlog included such designs. This mean that as components were killed off in the old system, when they arrived in the new, they went beyond “minimal viable product” matching of needs. There are risks with that if it is not infinitesimally cheap to do it - get the split wrong, and you risk cancellation from stakeholders. That’s both too-little as well as too much.
Testing at every level was taken on by the development team - unit tests coverage was at the 90% mark. Integration and functional tests (ThoughtWorks’ Twist product) figured too, and even helped speed up regulatory approval.
A Personal Management portal
This was a migration from mixed Java web-technologies to JRuby on Rails with more Web 2.0 features than before, from 2009 to 2012. More than a migration, it was a consolidation. From the customer’s point of view there was a high percentage of new functionality developed. That the strangulation was happening concurrently, was almost secondary, as the end-user experience was smooth.
Phased rollout: In the first year there were quarterly releases. In the next six months there was once a month. For the final year of the project, there was one release every two weeks.
National Supermarket’s internal planning app
This is a bricks and mortar supermarket outside the US. It has an application that is an internal one for assortment planning and execution (monolithic). Over multiple years, the database-centric Java+Swing app will be migrated to Rails, with micro services in Java. For one, business logic will move out of the database and into the micro services. The new solution is checked in to a modern DVCS with separate repositions around business function.
There’s no smart proxy solution fronting old and new (like InkBlot above) as the technologies are quite different. The end-users are internal of course, and training helps overcome the gaps.
The plan is more of a programme than a project, as there are multiple systems that are yet to be pulled into the new solution, and the planning of that is relatively complex. Deliberate slices are around clear categories of business functionality - Pricing, Supplier Contract Negotiation, etc. The programme will see a significant peak soon in that it migrates a very significant piece. After that the strangulation releases could speed up, as a dependency graph indicates things will get easier.
The first strangulation deployment went out within a couple of months of starting the project, and monthly releases have happened since then.
The business stakeholders were guarded about the value of the approach, but are all fans now.
Used consumer goods magazine’s web portal
Migrating from Oracle Endeca to newer Java/JavaScript technologies the project was as much about consolidation of many smaller apps, into a single architecture as anything else. The strangulation aspect of the build-out took a year (a few years ago), and the client was keen to be analytical between releases to be sure that the end-users were not discouraged. Towards the end of that period, A/B testing was integrated into the rollout schedule.
The style, and to some extent interactive function of the old site, was reworked to match the new one from an early stage. As they intended to ultimately delete this code, you could consider that to be waste, but it wasn’t really as strangulation is generally a cost and risk saving route. A proxy fronting the experience made it all feel cohesive to the end users.
The client’s main item for sale was the principal focus of the project, but closer to the end, some of the ancillary product categories were brought into scope.
There was some skepticism about essentially wrapping the previous site, but that dissipated as rollouts proved successful. The first strangler release was six months or so. Subsequent ones were weekly for a few months. The business wanting to carefully analyze usage (as mentioned) was a factor to slow things down, if you consider weekly to be slow.
Artichoke - a bottom up rewrite of Ruby
(Added July 3rd, 2020). Nothing to do with ThoughtWorks this time: The Ruby language has multiple compantible version (JRuby etc), but the core implementation is “Matz Ruby” MRuby. There’s a team on GitHub rewriting the lower level porions of MRI -bit by bit in Rust. They’re doing so as a strangulation and not as a rewrite. Thus, at any point you could arguabley use this Ruby for a production use. The project is called Artichoke and they’re noting small performance gains as they go as measured in executions of the test suite. Great work Ryan Lopopolo, KY, Serj Krotov and friends!
When I first latched on to Rust, I though that it was inevitable that much of the more pleasant HLL’s (and more) would be rewritten piece by piece and bottom-up. See https://twitter.com/paul_hammant/status/1044671937543380992
More Information
A ThoughtWorks Quarterly Technology Briefing
Badly received cases for big-bang attempts for Hershey’s, FBI, and Windows Vista are talked about by ThoughtWorkers Amit Uttam and Derek Longmuir at a Quarterly Technology Briefing in 2010. Twenty Eight minutes in Derek describes the approach.
Pretotyping
Refer www.pretotyping.org
Two Googlers (Alberto Savoia and Patrick Copeland), and their buddy (Jeremy Clark) champion this cause. Part of their approach to application construction, is to leverage pre-existing systems were possible, even if they are suboptimal or to be replaced. Their prerogative is cheap prototyping and faster failure/cancellation if that is appropriate. Actually it is much more than that, and you should watch their video.
Chrysler’s C3 Project
Agile luminary Ron Jeffries remembers the cancelled C3 project at Chrysler(half way down) a lot more than ten years ago:
We should have replaced the broken bits,
one at a time, most valuable first.
He’s lamenting not doing a strangler approach to migrating from old to new, as well correctly determining which bits to prioritize (and de-prioritize).
For those considering strangulation
As mentioned before the nature of URLs make this type of strangulation particularly suitable. Going from a C++ design to something more modern is a probably the most encountered case today. You could go from Java to Ruby/Rails in the same way, but also from Java to Java if the frameworks in question are not immediately refactorable, and the benefit numerous. Indeed, for that particular approach, you might be moving code, sprucing it up, and adding unit tests, rather than rewriting.
There is an aspect of my previous published “singleton escape plan” that is similar to that, although the lack of strangulation is the key difference as this was an incremental improvement of a functioning application with an aim to avoid replacing it.
In terms of technologies, you could use a load balancer (as mentioned above), but you could also do this in a more conventional “reverse proxy” style of web technology. Apache with suitable modules, as well as HAProxy are both good choices. Joshua Gough, in the Agile industry, was part of a web-app replacements effort and detailed links from old app to new one (and vice versa). It could be obvious that two applications are in play if you watch the URL, but it may be seamless in experience and aesthetic. I prefer something in front of both proxying to old or new appropriately. If it isn’t obvious, the very nature of URLs (at least where there are directories in them for subsections of the app) helps give you seams to work with (one at a time), to make for a safe migration from old to new.
Colleague Jez Humble has written about Branch by Abstraction (warning: links back to me), and how that’s related to Strangler approaches. Associated too, are Feature Toggles, and good OO practice.
Best Practices
The Andy Pols & Chris Stevenson paper has best practice defined throughout, which you should read. The Joshua Gough blog entry (same link as above) repeats some, and says a little more - and should also be read.
Her’s mine though (additive again), after talking with colleagues about the Strangulation pieces we’ve done in the ten years since InkBlot had ThoughtWorkers in the team:
- You really should phase the strangulation. Keep your larger app in a continually deployable state while working on it. The first go live after a month or so of work, then every two weeks after that at least or you’ll fail. That would probably via project cancellation by a checkbook-holding sponsor.
- Do enhancements or new “business value” work concurrently with strangulation, while getting all to agree that both are happening. As you work on the strangulation, a decent percentage of work should be enhancements too. This allows value to be associated with each release from the point of view of the people paying for it. ROI and all that, isn’t just abandonment of costly end-of-life IT choices, it is about tangible changes for the better. From top to bottom, everyone needs to agree that both are happening.
- The additional of integration and functional test suites as a safety net is key. This is particularly true for when the old technology did not have unit test coverage. The functional tests will be able to step between old and new (and back), to prevent surprises.
- Understand that Non functional Requirements (NFRs) that don’t directly cheapen the re-implementation may jeopardize the initiative. Jeopardize in the “courting cancellation” territory again. Various authority figures may have pet technologies to include, or things to exclude. The test is whether the dev team cranking stuff out agrees or not.
- Agile methodologies optimize everything for maximized developer throughput, and phased deliveries to production. You will not manage this with waterfall, unless you want glacially long intervals between production pushes. The Pols/Stevenson white paper (same link as above) drills much further into the Agile aspects.
- Lastly, you should always be aware that there could be functionality and context hidden within the old application that people have forgotten about, and that a team of business analysts assigned to reverse engineering behaviors might also miss. This is a risk for any “rewrite” though.
Thanks
Thanks to Joe Walnes, Chris Stevenson, Andy Pols, Nick Pomfret, Ben Hogan, Martin Gill, Kent Spillner, Tim Reaves, Graham Brooks, Prasanna Pendse, Vladimir Sneblic, Samir Seth, Carlos Lopes, Sam Newman, Sean Doran, John Spens, Jez Humble, Thiyagu Palanisamy and Ross Pettit.