Paul Hammant's Blog: Open Data backed by Source-Control
Things being backed by source-control is a decade-long obsession of mine. This time: “open data”. If a thing can be represented by a textual document, is structured or regular, and tends towards completeness over time, then source-control is an viable alternative to a relational schema (or a document store). JSON, provided it adheres to a standard/tidy/pretty format is particularly good for source control, although semantic merge would make that even better.
Examples
I’ll go into a couple of examples..
Food Nutrition Tables
I made a GitHub repo for Nutrition data, and a Tiny AngularJS (five lines of JavaScript) app to present the same data to humans. Consider Cupcake (click it to see the real thing):
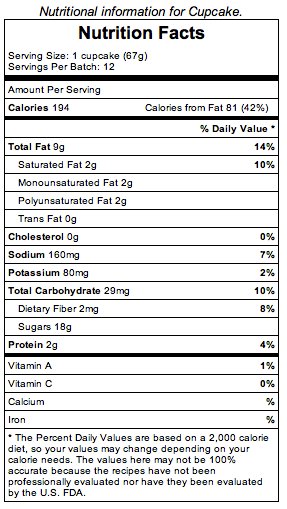
Cupcake has Raw Data like so (again click it to see the real data):

It is easy to see how you could collect nutrition info in a Github repo. Not just generic foodstuffs, but also brands (assuming litigation did not try to stop that). It’d be nice to see per 100g quantities as well, as there’s some rounding down allowed in the US for sub one gram quantities in a ‘serving’. The application I made (I cribbed code from Jonathon Cihlar’s 2007 blog entry on nutrition tables in XHTML and CSS ) is output only; You would have to push data into GitHub manually.
US Hotel Data
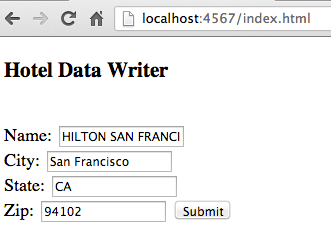
This one is much the same idea. Colleague Andrew Dean led the development of it (at a ThoughtWorks hosted ‘GeekNight’ in Dallas some weeks ago), and I’ve forked it on GitHub to push it a little further for this blog entry. This one is not a GitHub Pages thing. It requires a custom Sinatra server to allow data live editing – see the ruby script in the source root. That script uses a unix utility Jshon to tidy JSON source, as you want to minimize diffs when you’re committing to the source repo. Lastly, the commits don’t happen in the app we’ve made, although we know how as we’ve previously made a Sinatra app that did commit to github. Instead, you’ll have to do the commit yourself (for now), after editing data over http://localhost:4567. There are two pages for this (so far) -
An index page that asks for key fields for an entry, for direct access:
The resulting data page for that (note the URL is as the data in the repo – without the .json suffix):
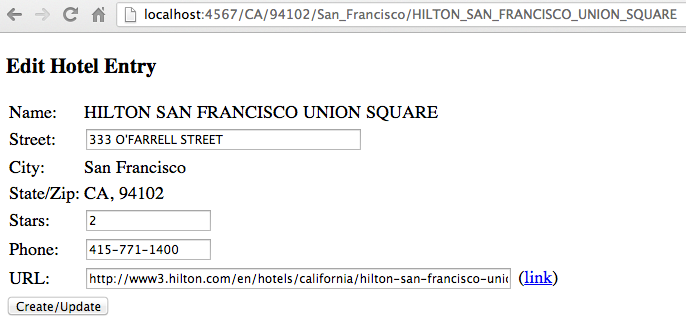
If you’re booting the app locally for you, that’s http://localhost:4567/CA/94102/San_Francisco/HILTON_SAN_FRANCISCO_UNION_SQUARE
We’re using Angular here again (ten lines of JavaScript), but not very effectively. We could have a drop-down for the number of stars, and a formatter/validator for the telephone number. The first page is not Angular at all, it’s an old fashioned POST page in the HTML 1.0 style. It could easily be a server side template that would also allow us to iterate over states (and zips, cities and properties).
GitHub?
GitHub could totally own this type of application. Freebase is not what I want, nor is the impressive JavaScripty competitor I saw discussed on Proggit or HackerNews some months ago (the link for which I can’t find presently). Neither uses source-control for storage, which would allow alternate routes to accessing and modifying the data.
With a small shim in GitHub’s infrastructure that could process PUTS and mess around with URLS for the sake of a GET, GitHub pages could accept writes of JSON content for authenticated and authorized users. Pull Requests could be a way of donating them back to the master repo. The GitHub folks would have to work out how to allow developers to program that server side handler (hopefully it would look like Sinatra).
Forks!
Then again, there could be forks of the repos that maintain divergence (also a blog entry) in that they add data that the master does not really want. For the Hotels example, one could have fork that adds “costs of wifi” (detailed in that blog entry). Nutrution Info could have forks that add “good/bad for Paleo diets”, which could also have a fork “good/bad for Primal Blueprint diets”. You get the picture hopefully.
Updates
See Git (and Github) for Data - July 2, 2013 by Rufus Pollock
I made a second branch that uses Firebase for the storage of the ‘open data’. Compare the two on Github (May 16th, 2015).