Paul Hammant's Blog: Scaling Trunk-Based Development
This is about how many trunks a team has, and how many applications they make from it/them. It’s pertinent to Trunk-Based Development (TBD), of course, which some high-throughput companies with many thousands of developers like Facebook do. They do it because developers merging to working-copy multiple times a day, and committing to a common place is the best way to facilitate speediest Continuous Integration (CI). Also, this article is not about how developers use DVCS on their own workstations, but about the shared/managed source-control repository common in enterprises.
Before we start, some definitions:
- Application - something you build and deploy, comprised of modules. One or maybe more processes.
- Web App - an application that uses a browser to interface with end-users.
- Web Service - an application that uses HTTP to interface to remote non-human things (this includes RESTful services).
- Module - something that is built and deployed with an application, that the application depends on (linkable objects including JARs, DLLs) which typically may have their own build file.
- Third-Party Modules - Modules not build by the organization in question, like Log4J.
- Process - as you’d expect: an OS launched thing built in a homogeneous technology (but ignoring whether horizontal scaling happens for the companies load requirements).
- Continuous Integration - how and when commits are automatically built, linked, deployed temporarily and destruction-tested.
A startup with one Web App
Let’s say this startup has a single Web App written in PHP and using an DB (MySql or Postgres) in 2004. It is a social network, and we’ll call in Bookface. All the technologies were great choices for this thing. There’s some horizontal scaling, but that’s of identical processes. Ignoring Apache, any load-balancer (and infrastructural pieces), the dissimilar process count is 1:
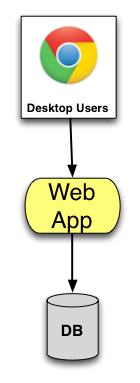
According to our invented history, Bookface had a single trunk (Subversion). Lets plot that number of trunks to the number of applications on a chart:
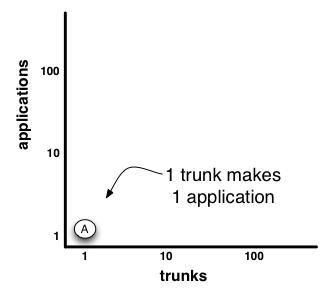
The hypothetical site (www.bookface.com) may or may not comprise a number of modules, but all of those modules can be built in series in a single invocation. Bookface do not need CI yet, but would be much better with it. Mere ‘Rigor’ around commits in a Trunk-Based Development (TBD) setup, will only get you so far for so long.
The single trunk, and single app, we’ll refer to as ‘A’, and accept that is a how Bookface started.
Making more than one application?
Specifically, what do Bookface do when they start their next application. Say that is an iOS or Android thing that provides a second way to see/manipulate data. Perhaps they’d deploy a Web Service built in to the main Web App. Alternatively they might deploy the same web service as a standalone process with it’s HTTP interface, with the ‘old’ Web Application depending on it. If it’s a standalone, they might deploy it at the same time. If they don’t deploy always at the same time, then the web-service own release cycle and forwards/backwards compatibility, and must be measured against Conway’s Law to ensure that it’s not gratuitous. Here’s that stack with an additional Web Service tier now:
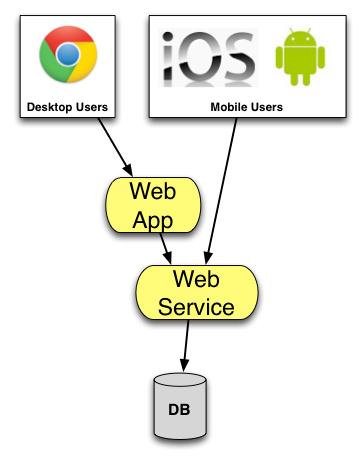
In terms of their production stack, the dissimilar process count is now 2. That’s the Web Application and the Web Service (as before we ignore infrastructural pieces, they did not compile themselves). In terms of applications, the count is now 4: 2 + 1 (Android client) + 1 (iOS client).
Bookface now has choices as to the organization of source in order to make making more than one application. I’ll outline them these alternates (‘B’ through ‘D’ below). They are certainly not a progression:
B: Having all source in one trunk
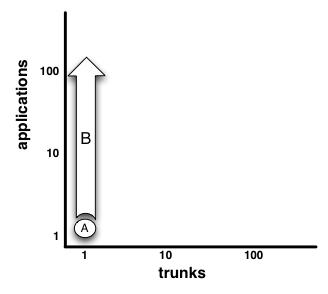
Bookface have the source for all four applications in one trunk. They kick off a build script from root, that knows which application it is building. With that knowledge, the build script subsets the trunk into only the source/modules that need to be built for that application. In Java-land a maven profile that created then build a directed graph of sub-modules is popular. That’s not the only way though for Java.
Each application release according to a different schedule, which means release branches may contain source code that is not going live at all. Nobody really worries about this, as branching is not costly in the modern source-control tools, and there’s trust in (and verification of) the build scripts.
Note though, this absolutely cannot be done without some really hard-core CI pipelines (read Jez’s book - Continuous Delivery)
Benefits
- Common code ownership.
- Continuous Integration that reports defects with seconds of them being committed to the trunk.
- Ability to deploy separate applications separately.
Challenges
- The “Diamond Dependency” Problem requires clever thinking to solve, if all dependencies (particularly Third Party Modules) have to be in lock step (they do).
- Having a supported workflow for developers changing code that’s not in “their” module (thin vertical slices).
- Making sure changes to shared modules are fully tested against tens or hundreds of applications that use them before committing.
- Making sure changes to shared modules are in line with the directions of the 10s/100s of apps that use them.
- Worrying about the size of representation of the ‘checkout’ on the developer workstation, maybe needing tooling to reduce that.
- Worrying about the update/sync/pull/fetch duration being a disincentive to doing it 20 times a day, needing tooling to reduce that.
C: Separation into a small number of repos/trunks, many more applications.
This is like ‘B’ above, but there’s a modest split of source code between two repositories. Say ‘front-ends’ and ‘middle-tiers’ for Bookface. For ‘middle-tiers’, all Web Services that pertain to the Web Application, the iOS client, and the Android client go out in one deployment. It does not matter which one is needed for a release, they are all part of the same process in production. That’s just one way of slicing source, and grouping deployments. Another could be that you make separate processes for each of the Web Services, (even on a release branch), but choose which ones go out in each deployment.
It seems to me that there is not enough difference to ‘B’ to make any benefits clear, and that this only introduces management and CI-ordering overhead.
D: Many trunks, many applications
Bookface decided to make a trunk/repo for each modules. Perhaps these were those modules in separate repos/trunks: bookface-persistence, bookface-logging, bookface-admin, bookface-operations, bookface-web, bookface-cdn, bookface-orm, bookface-rules, bookface-services and bookface-temlating.
It is likely that they also made some team separations for all or many of these, and reflected that in the organization. Companies doing this might be doing feature branches rather than trunk based development.
Benefits
- Suits a very hierarchical organization of development work, including permissions for separate repos/trunks.
- Discrete versioning of individual pieces.
- Diamond-dependency problem reduced.
- Developers only checkout what they are working on.
Challenges
- Not seeing a reduced developer throughput.
- Maintaining versions for dependencies in build files in many repositories/trunks.
- Making sure developers update/sync/pull/fetch all the repos that they are working on frequently enough.
- Having tooling for developers to acquire appropriate binary versions of dependencies from repos/trunks they are not working on (they don’t have a checkout).
- Using CI effectively to integrate ‘latest’ of all. In reality, this pushes your integration testing towards release dates, meaning you’re risking cost-of-change issues, which is the antithesis of CI.
- Having channels for developer asking for changing to code that’s not in “their” module.
- Making sure changes to shared modules trigger automatic rebuilds/tests of modules that use them.
- Preventing Conway’s Law from seriously impacting nimbleness.
Last thoughts
Summary
Here is an attempt at a summary:
| Aspect | A | B | C | D |
|---|---|---|---|---|
| Continuous Integration | Fast | Fast with tooling | Fairly Fast | Slow or Late |
| Common Code Ownership | Yes | Yes | Some | Not Really |
| Thin Vertical Slice | Easy | Easy | OK | Hard |
| Versions of Modules | Don’t Think About It | Don’t Think About It | Some Manual Accounting of Versions | Much Managing of Version Dependencies |
| Releasing to Prod | Turnkey | Turnkey per App | Think About Dependencies | Worry About/Manage Dependencies |
I prefer ‘B’ if it wasn’t clear: All source co-mingled in one trunk, taking advantage of lightweight branching of modern source-control tools. I’ve seen it work at huge scale.
MicroService Architectures
Companies implementing MicroService Architectures could be doing any of these. MicroService Architectures is more about fidelity of deployment than organization of source. I think such companies can be perfectly successful with a reduced amount of trunks (‘B’ or ‘C’), but ‘D’ might be common.
Cookie Cutter Scaling
Companies doing cookie cutter scaling are likely to be doing ‘B’ or ‘C’, and very unlikely to be doing ‘D’.
Facebook?
Bookface is a reverse engineered beginning to Facebook. I’ve no idea about the development realities of their early days.
We know that Facebook use one trunk for their main PHP website, and used to have a special compiler to make that into a 1Gb exe, but now is a VM solution. Where the source code is for lower tiers of their stack (same or different trunk/trunks), and what paradigms they have for releasing ‘services’, and whether that’s at different moments to the Web App, has not been talked about yet.
Google?
We know they use Perforce, and have hundreds of applications. They have not talked about their branching model, though they have talked about many aspects of their build infrastructure on their engineering blogs. If anyone has links that publicize any more information about Google, please email me :)
Thanks
Thanks to Mark Needham for some comments before publication.