Paul Hammant's Blog: Web-app model quandary
Web applications take effort to develop for the most part. Serving static pages is much easier. Over the years the patterns and techniques to develop web-apps have changed, and so has the division between logic we write on the web-server tier versus logic in the browser. We now write much more logic in the browser, and indeed we’re on the cusp of an era where Model-View-Controller (MVC) in side the browser is the dominant design. Micro-web-frameworks have made that possible, and there are new problems to solve.
In this blog entry, I outline the difficulties making solid web-apps where the model is being heavily mutated. Earlier today I mulled the technologies in play in 1993, 2000 and 2006 for enterprise web-applications, and this blog entry is intended to continue the cataloging of technologies to the current day.
2012: The Micro Web Framework era.
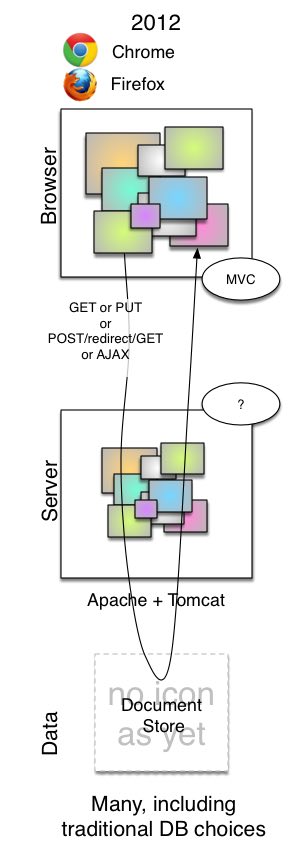
I’ll phrase this as a status quo for the technologies in question.
Micro Web Frameworks are largely divorced from the back-end server technology that hosts the larger web app. As such, we can consider them interoperble with many alternate backends. In that web-server tier, Rails is still an immensely popular technology, but there are new kids on the block: NodeJS, Grails (Rails for Groovy), Scala’s Lift and Play. Rails has competition with Sinatra. It ate its previous competitor - Merb and Rails merged to form Ruby on Rails 3.0. SpringMVC and the one of .Net equivalents are one more the more ‘safe’ enterprise choices. WebSockets and HTML are the cutting edge. PHP is still an amazingly popular choice for startups of course.
The frameworks competing in this space include Backbone, Knockout, KnockBack, Spine, Ember, BatMan, Angular, Sammy, JavaScriptMVC, YUILibrary, SproutCore, Broke and Fidel which all ship as JavaScript scripts from 30K and upwards. The genus kicked off in 2009, but the competition did not heat up until the middle of last year. They are all variations on an MVC theme. HTML markup is kept (and the tool-chains and techniques around that). But the page is now able to have programmed series and other turing complete functionality with an absolute minimum of hand crafted JavaScript. The libraries perform something akin to magic to rewrite the page according to JSON data sources and a meld of more functional enhancements to HTML (that the library recognizes), and a spattering of JavaScript for the more advanced functions.
Back in the web-server tier, the chore is now serializing to and from JSON. Some languages have that built in, some require libraries. Java’s XStream falls by the wayside for Java as it is better transforming to JSON than from it, Luckily there is GSON and Jackson. Indeed having classes that support specific hierarchical structures of JSON is the challenge. The dynamic languages have the advantage of course.
But where should the dominant model be?
The shift in onus is from the model being (mostly) in the web-server tier, to there being no clarity about whether the model is there or in the browser tier. This is the inherent problem right now. A starting position for design (once you’ve decided to go with a micro web framework) is to have the browser tier do all the MVC for the app one ‘page’ at a time, and retrieve JSON from a vestige app-server as well as put it back when done. That makes the back-end more of a document store, and thinner by necessity. It is easy to see that the persistence technologies built to support such apps should naturally retrieve and save such documents rather than normalized sets of records. Old fashioned DB technologies (Oracle, SQLServer, MySql) still have a place, but the direct page-supporting tables should be more like document stores, and have CLOB fields to hold JSON, with simpler key fields. You should be more drawn to the likes of Cassandra, MongoDB, or CouchDB really though.
With these browser-based MVC designs, if the web-app tier is doing any business logic, it is validating data a second time, as one can’t really trust what goes on in the browser with the likes of GreaseMonkey and Firebug around. If it finds validation issues, it is more than likely to send that back to the browser for re-presentation. An easy way to do that would be to embellish the document received with errata, and have the MVC app just display them inline. More about that in a follow up article.
Things get more complicated when a larger document is served to a HTML page, but only smaller sections may be changed at a time. There’s a temptation to POST back the subsection, have the backend validate/persist that, and simultaneously rework the model in the browser to reflect what “would have been served” for the whole document. Why not PUT the whole document to the backend, and reload if needed? If the document is as big as a word document, and your app functions like GoogleDoc’s word processor, then it would die with the overhead of the whole document going up and down per keystroke. Google, has a very efficient wire language to describe the keystrokes being made in a POST operation labelled ‘mutate’. It hints that their model is mirrored to both sides of the wire. It has to be really, as other people can concurrently edit Google Docs.
The GoogleDocs design should make us hope for safety and transactionality with apps that use micro-web-frameworks. The Page could be alive a long time without pushing data back to the web-tier and hence the data storage. A beautiful aspect of MVC is the fact that you can in fact abandon (garbage collect if you like) the model, if the changes it holds is no longer required. The older data-binding style of models is much harder to coerce into abandoning DB writes if required. GoogleDocs allows the rolling back of a series of changes. It feels more like a source control system in that respect. Yet, as long as you are connected, everything is safe, and the chance of loss of data is down to a small number of keystrokes (and for when the browser/machine fails).
By contrast the traditional install of Microsoft Excel means that it’s going to be editing a file-system available XLS document. While you’re editing it, it keeps a backup version just in case it crashes for some reason. You could safely reply on that backup, until you’re ready to for a formal SAVE and close of the worksheet. Your alternate is to close without saving, which is the equivalent of abandoning the changes. With either action, the backup file is deleted. Excel’s metaphor allows for working detached from the network which is handy in for “on an airplane” scenarios.
An SCM-like Workflow?
Is there a model where the web-server initiates a workflow for ‘record’ of some sort, where work is ongoing on that record, and will be completed later? Maybe the record is locked for the duration. maybe not. That would be ‘work-in-progress’ and the representation of it should be mirrored like in GoogleDocs. All changes to it would be safe. You also get the late “submit” or “abandon” reality of a detached model. As it would be document-centric, there could well be a “diffs” that describe the modifications from a starting position, or from last advice. That loses some of the intent of the changes being made though. Martin has an article from seven years ago on Event Sourcing that is well worth a read. Event Narrative is a follow up. Martin is much clearer on the chronalog of changes made to a model, during an implicit save/publish phase. Would the micro-web-frameworks grow a synchronization side that can keep a backend informed with deltas every few seconds? Right now you’re on your own. You write code to POST fragments to keep your models in sync, or you push whole documents. There’s no mirror/sync capability built into the current micro-web-frameworks. The metaphor for the intended save or abandon, feels closer to the commit/merge concept from source control systems.
2/8/12 Update:
Alan Huffman, in email, says the name for what I’m talking about here is “Client-Side MVC”. Yep, that’s it - nice and short.