Monorepo Build Systems
Or rather: Google's directed-graph build system for monorepos with special sparse-checkout features versus classic depth-first recursive types.
Fewer than 100 companies worldwide should consider the same setup.
For all others, this talk is just a curiosity.
For all others, this talk is just a curiosity.
Talk by Paul Hammant
I have a bunch of online resources about Trunk-Based Development (TBD) spanning back 15+ years:
- trunkbaseddevelopment.com
- paulhammant.com/categories#Trunk-Based_Development
- This video tbd-book.com/gmr-vid
I have a book on TBD which covers this stuff too: tbd-book.com
See also, my book, Value Stream Mapping for Software Delivery Teams, which doesn't cover this stuff but is very interesting: vsm-book.com
Talk Roadmap
Directed Acyclic Graph build systems
- Google's Piper and rationale
- Simulation Project on GH with contrived app
- Talk through various build & test scenarios
- Build tech aware sparse-checkout capability
Potvin & Levenberg's monorepo paper refers to this as subsetting on their "clients in the cloud" (CiTC)
Depth-first recursive build systems
- Same sim repo, different (divergent) branch
- Talk through various build & test scenarios
- Discussion / Pros & Cons
Google's Piper VCS & build system
- 1000's of applications and services comprising 9+ million source files in one branch (trunk) of the monorepo, horizontally scaled to support 25K+ committers with 90TB+ of history
- Clone of all that to one workstation isn't possible
- Even if it was, the checkout alone would kill your IDE
- Devs+QEs use a tool for smart subsetting and a build-system that works well with that (Bazel)
Google's rationale
Their monorepo approach allows Google to make atomic changes
across multiple projects simultaneously,
maintain consistent dependencies,
and very effectively share code at source level across their entire engineering organization.
Important: Dependency management this way allows lock-step upgrades without lock-step releases, and enable lower-drama large-scale refactoring
Directed Acyclic Graph build systems
Google style
Modules & Classes Used in the Simulation Repo
Two main() applications with some components in common
Simulation GH repo
If you're a minimal cloneable example learner*, you'll pause this video to git-clone right now, then listen in background as you try things yourself
Small print: this uses Git because we don't have Piper to play with
Module Dependencies
Instead of Bazel's BUILD files, modules have .compile.sh
and maybe .dist.sh or .tests.sh scripts.
A module dependency declaration:
# From javatests/components/vowels/.tests.sh source file deps=( "module:java/components/vowels" )
☝ Tests for components/vowels depend on prod code for the same to compile and run
Dependencies can be binary too
An example binary dependency declaration:
# From javatests/components/vowels/.tests.sh source file bindeps=( "lib:java/junit/junit.jar" "lib:java/hamcrest/hamcrest.jar" )
If you were using Git for your corporate monorepo, instead of a Piper-alike,
you'd likely be using Git Large File Storage (LFS) to keep the binaries out
of the clonable (history-retaining) .git/ folder
Compile of one application
and its deps and make jar
./java/applications/monorepos_rule/.dist.sh
MonoreposRule Instantiation
$ java -Djava.library.path=. -jar
./target/applications/monorepos_rule/bin/monorepos-rule.jar
libvowelbase.so extracted successfully.
main() .. MonoreposRule instance created:
M(O)N(O)R(E)P(O)SR(U)L(E)
MonoreposRule{m=class components.nasal.M, o=class component...
Each letter of the app's class name prints to stdout (in the class name of the c-tor).
Vowels do that too, but wrapped in parentheses by the Rust code (via Jav native Interface - JNI)
Tests for that app
(and compile of deps)
./javatests/applications/monorepos_rule/.tests.sh
Note: Tests and prod-code are single "participants" in this seq diagram
Tests for app and tests of deps
./javatests/applications/monorepos_rule/.tests.sh --test-deps-too
Note: Tests and prod-code are single "participants" in this seq diagram
Run all Java tests in the monorepo
./javatests/.all-tests.sh
- Automatically discovers and runs tests for all java modules
... after building their dependencies - Works with the sparse-checkout, if active
- You might do this for your Continuous Integration daemon
... would need an `--impacted-only`
feature before (say) Google would use it
Monorepo Tests
Running "All tests", could include a lot of slower browser-based UI clicking tests
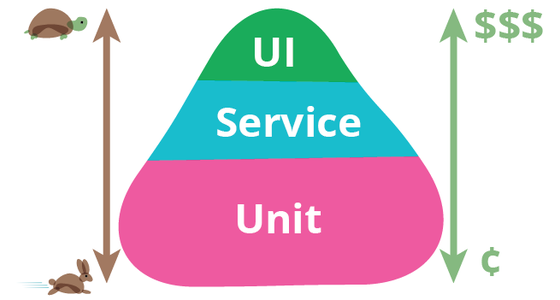
^ Martin Fowler's pic here, of Mike Cohen's pyramid:
Maybe you'd fast fail for very quick 'unit' ones first:
for typ in unit service ui; do ./javatests/applications/monorepos_rule/.tests.sh -tdt -$typ done
Monorepo Tests (continued)
Or something more sophisticated:
set -e cd javatests/applications/monorepos_rule .tests.sh -tdt -unit && .tests.sh -tdt -service \ && .tests.sh -ui
(Confession: I have not coded the 'type' switch)
Google had unit/service/ui mapped to small/medium/large (link to article by Mike Bland)
Sparse checkout in a Google-style monorepo
I've made a cut-down representation of Google's tech with crude shells scripts
This tech hides directories that are not pertinent to the thing you're working on. For example monorerpos_rule app does not need you to have directed_graphs_build_systems_are_cool in your checkout, does not need a bunch of the unreferenced components
Another shell script
$ ./shared-build-scripts/gcheckout.sh
Usage: ./shared-build-scripts/gcheckout.sh add <module_path>
| --init | --reset
$ ./shared-build-scripts/gcheckout.sh --init
Initializing sparse checkout with --cone...
Sparse checkout initialized and shared-build-scripts added.
Usage: ./shared-build-scripts/gcheckout.sh add <module_path>
| --init | --reset
$ ./shared-build-scripts/gcheckout.sh \
add javatests/application/monorepos_rule
...
See live demo
Great Value in the DAG
Google's directed graph of module interdependencies has been curated over 25 years.
First by humans (devs, QEs, SREs). Soon after bots/scripts offered advice too.
Doubtless LLMs give insights these days. Code review comments:
- "too big, make two optional child modules"
- "too small"
- "duplicates the intentions of another module"
Depth-first recursive build system for comparison
Same two contrived main() style applications.
Same shared components.
Same Java calling Rust duality.
Depth-first recursive sim
Same Simulation repo - different branch:
The classes are the same, but in different directories.
Maven's pom.xml replace the shell build script - one per module.
Maven Build for one application
./quieter-mvn package -pl applications/monorepos_rule -am
<Rust compilation output> rust compile for components-vowel-base java compile for components-vowel-base java tests compile for components-vowel-base test for components-vowel-base jar for components-vowel-base copy-resources for components-vowel-base java compile for components-vowels java tests compile for components-vowels test for components-vowels jar for components-vowels java compile for components-nasal java tests compile for components-nasal test for components-nasal jar for components-nasal java compile for components-voiceless java tests compile for components-voiceless test for components-voiceless jar for components-voiceless java compile for components-sonorants java tests compile for components-sonorants test for components-sonorants jar for components-sonorants java compile for components-fricatives java tests compile for components-fricatives test for components-fricatives jar for components-fricatives java compile for monorepos-rule java tests compile for monorepos-rule test for monorepos-rule jar for monorepos-rule uberJar for monorepos-rule
Maven's reactor picks the order upfront - with fast fail
Maven Reactor Sequence Diagram
Discussion
Depth-first recursive versus Direct acyclic graph build systems.
Limits of the sparse checkout tooling I made. Sparse capabilities in depth-first
recursive build systems
My sparse-build tech doesn't have
- A generated reverse map: "what uses java/components/vowels?"
- Query interface
- Add those to checkout via single "add depending" script invocation
- Map could be in the Git repo ... but probably shouldn't be.
- Google talks of a "Kythe" code indexing tech that maybe has these features.
- Fast fail scripts for a commit-hook to use:
"your sparse-checkout should have /ts_tests/foo/bar/baz and 12 others as you have changes in /ts/foo/banana"
Shell scripts vs Bazel
- ✓ Easier to understand with no prior-experience
- ✓ Zero install situation
- ✗ Without a purposeful build language (starlark), it is easier to make an inconsistent mess
- ✗ Some repetition of lines (not DRY - oops)
- ✗ Forget about fine-grained dep tracking, hermetic builds with reproducible outputs, distributed build cache that works across machines, remote execution and parallel building, better handling of cross-language deps
DAG advantages over depth-first
- Lockstep upgrades of modules and binary deps - restating that doesn't also mean lockstep releases
- Other consistency aspects perhaps (noting Ralph Waldo Emerson on that)
Many other claimed advantages could be implemented as features for the depth-first build systems if they wished, including the sparse-checkout tricks and compatibility
DAG build system disadvantages
- Some classes of problem discovered late in execution
- ?