Paul Hammant's Blog: Another UI prototyping technique (for Agile teams)
[TL;DR]
Use Firebug, another plugin, a Python script and Subversion (or Git) to model both progress towards web-app completion, as well as proposed changes. Works for Agile methodologies only. Better than Photoshop.
[For those without ADHD...]
A ThoughtWorks project I know uses Mingle for story management, and Photoshop for comps (page mockups). ThoughtWorkers like the former of course, but not the latter. Photoshop is wrong because it is a static model of the experience. Specifically for an enhancement to the UI, do you start with the Photoshop files that are allegedly definitive for the site in question, or screenshot a new version of the site? Where and how are such Photoshop files stored, and are they versioned? What is latest? Are they deltas versus some other interim delivery of functionality, or a picture of the end goal? If they are the end goal, you are more likely to be on a waterfall project than Agile.
Mingle is not a great place to dump a series of graphic files and deftly navigate them while trying to simultaneously read BDD scenarios for them. Sure they are displayed inline, but you are committing yourself to a fair bit of scrolling in order to understand the story before coding it. They are also a moment in time. When you revisit a story to fix a defect, you might notice that the inlined screenshots are out of date already. Or you may not and erroneously do more than fix you defect. It is difficult within a story tracking tool to see the progress made for a single page, and tell what is current and what is out of date.
The client development team in question had a lunch time discussion on what to do next. There was agreement to move the images out of Mingle, and we believe having one owner would be better. There are more stakeholders involved, so they they have more people to consult before actioning anything.
Meanwhile I had a thought that web-site page mockups are better done in HTML than in Photoshop. Obviously that's not a unique thought as tools like DreamWeaver have been trying to do that for over a decade. There's also KompoZer (which I'm using to write this). These two are not good enough for highly compositional and fluid interfaces, and ordinarily that would drive us back to Photoshop and we would have no proposal in this blog entry. Various aspects of the idea are outlined below.
Consider the 'one-line summary' for a hypothetical agile story: "Ensure Martin Fowler is prominent in Google Instant". We will imagine I'm a Googler rather than a ThoughtWorker, and imagine I could implement functionality in Google Instant.
Here's what the required functionality looks like (click for full size):
We're going to come back to this story in a minute, but consider it already complete and ready to go live.
Firefox has a 'save-complete' feature which is not quite right. There's an Addon called Mozilla Archive Format (with Faithful Save) that does a good job of making a self-contained archive. Install it then play with it for any page (Tools->Mozilla Archive Format->Save Page In Archive). It makes a zip with a '.maff' suffix. You probably want to have the page title to be in the archive file name, which requires setting that as a pref in the addon.
Inside the zip file there is a numbered directory that's part time-stamp and part random number. Inside that there are two files: index.html & index.rdf and also a directory index_files. It is very similar to the "save complete" workflow that's built into Firefox, but the zip nature and standardized 'index_files' are the differentiator. The main page that you saved is index.html even though that almost certainly was not the name of it when it was online.
Here is what that looks like:
If you load the MAFF file (or the index.html file in the unzipped version) back into firefox it renders page as it was when you saved it. Even if you are offline, and the original website is down. If it did not do that then the whole proposal is vaporware. Luckily for us that worked in the test we did.
For our 'instant search' for Martin Fowler
I post-process the zip file to:
For Subversion the trunk/tags/branches naming standard is not so applicable for storing UI snapshots. I might myself have 'progress' instead of trunk. It could be that you are using Selenium 2.0 to do that as part of your automated functional test suites, but the Selenium team is going to have to work out a way to interact with the browser's UI to do that.
What I have with this now is the ability to save the progress of the development of the website. With some more scripting I could make a movie of evolution of the web page.
Source control is the main reason we are using the broken-out files, rather than the MHTML format that the MAF plugin also supports. The problem with that format is that resources are combined into the same source file making it much bigger. Thats not a problem for some people of course, but there diffs will contains lots of noise which would be unacceptable to me.
Diffs are also the reason I'm essentially un-pretty-printing the HTML that I'm pushing into source control. Indented HTML will make for lots of noise in a diff for the current generation of SCM tools.
To read the contents of the MAFF archive, and make them suitable for pushing into source control, I have a Python Script. It does steps 1 through 4 above:
Consider a new story: "Remove 'other services navbar' from top of search page while Instant search for Martin Fowler is in progress" (yes, it is contrived, and yes it is even further away from good story language). This is what that would look like:
If we load up the previous saved 'search results for Martin Fowler' page in Firefox, we have our starting position for the UI change. If I then launch Firebug and locate the div for the bar in question and zap it, I have the final visuals for this. Going through the save cycle again saves the final state of the page, and it will load and look as we would want. The above change is an easy operation in Firebug of course, and is barely worthy of a mockup before coding. You get the point though; I am trying to suggest a workflow for a designer, that is based on the working product to date.
For an Agile project, you hope the customer is sitting next to you so that you can model the proposed change. For high cost customers, you are going to have a proxy for them, but sitting next to the UI expert while the designer edits the UI is core to the proposal.
This way of evolving UI would only fit Agile development techniques, as there's always "working software" to base changes off. Also each proposed change (story) is likely to be an achievable delta over what was there before. Waterfall would only have a working web-app after many months of analysis/requirements/specification/coding/QA and those folks should stick to Photoshop imaginations of the future.
There are many Firefox addons that could be used for design changes within the page. Here are a reasonable subset: Web Developer DOM Inspector Color That Site! Pixel Perfect Styles Tuner EditCSS Browser Turns Editor Platypus Codetch Font Replacer SourceEditor XUL Gear
Where to store that proposed UI change though? The answer is a branch of course. You would have one branch per story. The branches will feel throw-away over time, as all you are ever really going to do is:
There are some subtle differences between Git and Subversion in respect of storing potentially fat repeating sources like images. Git only stores each item once in its repository. It will go to a lot of of effort to recognize an item as identical to another with a different name in a different branch, and only store another reference to it. Subversion will try to do the best thing when you make a lightweight branch. However if you try adding things again in different branches with different names, it will not be some economic with respect for repository bytes. Its a small difference though, both are viable.
Persistent viewing of UI snapshots
Subversion, for free, will serve up content on trunk or branches. Unfortunately that's not in a way that's amenable to in-situ functioning of a web page. For example this - http://svn.codehaus.org/paranamer/trunk/paranamer-distribution/src/site/resources/ParaNamer.jpg - is served by Subversion, but is not a jpg that can be in-line shown in Firefox. My Codehaus buddies would have to reconfigure Apache to add back mime-types to served resources. I have mentioned that before for my Cozmos side project. It is not so hard to do.
Sadly for Git there's nothing built-in that is good enough. Bart Trojanowski has made a CGI script for Git that is half way there. I am not sure it adds mime types though, and it only serves 'master' and not branches. Still it is a demonstration that it is possible to live serve from a Git repo. There could be other ways of doing the same though that were more cron-lazy-branch-and-cache centric suggested by a colleague Cosmin Stejerean that would work with Apache or Nginx.
I am really excited about the persistent online viewing of stories (whether pending or completed) because it will allow me to link from Mingle to proposed UI changes. It will also allow emailing of URLs to the business, who may or may not be interested in Stories per se, but certainly are about how it looks: no more fat graphical attachments going back an forth.
Luckily for us Firefox saves the final state of the HTML and resources mounted into the DOM. Google Instant is a good tool to trial this idea with as it is very interactive with the backend. Google Trends, for now, even shows that Google has trouble keeping with their own turbo-charged ajax "instant" search. Therefore using Google Instant (search) is a good way of proving that this proposed UI prototyping technique.
Would it be better though if the DOM were saved in some non-HTML way? Something like a JSON representation of the DOM? Or a series of JavaScript mutations to the DOM that yielded the same outcome?
We still have hopes that the diffs between the revisions would be terse, which means it could not rely on indentation. We also need developers to be able to understand the format so that they can reuse the achievements of the UI designer's story branches to change the applicable template page files in the app-dev trunk when the implement the stories.
So for now, maybe left justified HTML source is best. It minimizes the diff between revisions, and is directly reusable.
A file called ab5cdb1806fef4aa.html is one of the resources saved in the Google-search MAFF that we have been playing with. It is in each of the different MAFF files saved in our hypothetical flow. Unfortunately its contents are different each time. If we're saving many MAFF files to the same source root and hoping for them to share resources, then we would want referred resources to be uniquely named. That would mean code changes to guarantee uniqueness for your own situation.
An apology to UX folks
ThoughtWorks has User Experience experts who will be quick to tell me that UI is not UX. The latter is what we think customers should be buying and not 2D screenshots of course. Thus this proposal still falls short.
Sept 14th, 2010
(thanks to Mike Long for hearing me out first time, and finding the MAFF plugin (when I thought there were none), and Cosmin Stejerean for working through the implications for Subversion and Git, and helping complete the Python script)
May 1st, 2012
The Chrome team have made an autosave plugin that looks interesting.
Use Firebug, another plugin, a Python script and Subversion (or Git) to model both progress towards web-app completion, as well as proposed changes. Works for Agile methodologies only. Better than Photoshop.
[For those without ADHD...]
A ThoughtWorks project I know uses Mingle for story management, and Photoshop for comps (page mockups). ThoughtWorkers like the former of course, but not the latter. Photoshop is wrong because it is a static model of the experience. Specifically for an enhancement to the UI, do you start with the Photoshop files that are allegedly definitive for the site in question, or screenshot a new version of the site? Where and how are such Photoshop files stored, and are they versioned? What is latest? Are they deltas versus some other interim delivery of functionality, or a picture of the end goal? If they are the end goal, you are more likely to be on a waterfall project than Agile.
Mingle is not a great place to dump a series of graphic files and deftly navigate them while trying to simultaneously read BDD scenarios for them. Sure they are displayed inline, but you are committing yourself to a fair bit of scrolling in order to understand the story before coding it. They are also a moment in time. When you revisit a story to fix a defect, you might notice that the inlined screenshots are out of date already. Or you may not and erroneously do more than fix you defect. It is difficult within a story tracking tool to see the progress made for a single page, and tell what is current and what is out of date.
The client development team in question had a lunch time discussion on what to do next. There was agreement to move the images out of Mingle, and we believe having one owner would be better. There are more stakeholders involved, so they they have more people to consult before actioning anything.
Meanwhile I had a thought that web-site page mockups are better done in HTML than in Photoshop. Obviously that's not a unique thought as tools like DreamWeaver have been trying to do that for over a decade. There's also KompoZer (which I'm using to write this). These two are not good enough for highly compositional and fluid interfaces, and ordinarily that would drive us back to Photoshop and we would have no proposal in this blog entry. Various aspects of the idea are outlined below.
Firefox Addon live prototyping of page; Save to Source control
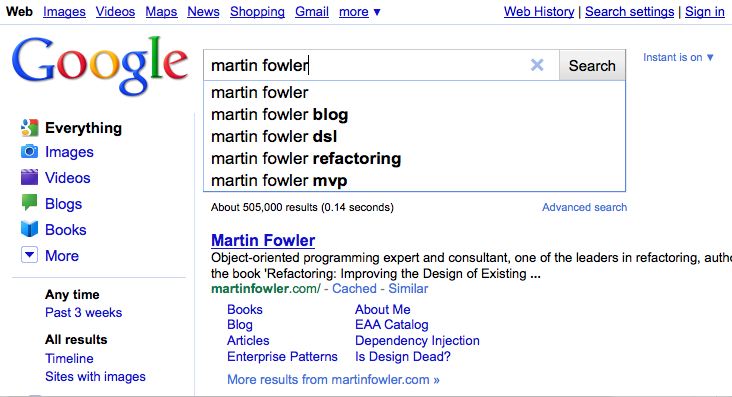
Consider the 'one-line summary' for a hypothetical agile story: "Ensure Martin Fowler is prominent in Google Instant". We will imagine I'm a Googler rather than a ThoughtWorker, and imagine I could implement functionality in Google Instant.
Here's what the required functionality looks like (click for full size):
 |
... going
to this page as I type into the the search field ... |
 |
We're going to come back to this story in a minute, but consider it already complete and ready to go live.
Saving the current version of the page to the file system
Firefox has a 'save-complete' feature which is not quite right. There's an Addon called Mozilla Archive Format (with Faithful Save) that does a good job of making a self-contained archive. Install it then play with it for any page (Tools->Mozilla Archive Format->Save Page In Archive). It makes a zip with a '.maff' suffix. You probably want to have the page title to be in the archive file name, which requires setting that as a pref in the addon.
Inside the zip file there is a numbered directory that's part time-stamp and part random number. Inside that there are two files: index.html & index.rdf and also a directory index_files. It is very similar to the "save complete" workflow that's built into Firefox, but the zip nature and standardized 'index_files' are the differentiator. The main page that you saved is index.html even though that almost certainly was not the name of it when it was online.
Here is what that looks like:
0 Sat Sep 11 18:01:00 CDT 2010 1284246060943_565/
202121 Sat Sep 11 18:01:00 CDT 2010 1284246060943_565/index.html
809 Sat Sep 11 18:01:00 CDT 2010 1284246060943_565/index.rdf
0 Sat Sep 11 18:01:00 CDT 2010 1284246060943_565/index_files/
17438 Sat Sep 11 18:01:00 CDT 2010 1284246060943_565/index_files/ab5cdb1806fef4aa.html
132640 Sat Sep 11 18:01:00 CDT 2010 1284246060943_565/index_files/I18TPaiRK6Y.js
34285 Sat Sep 11 18:01:00 CDT 2010 1284246060943_565/index_files/nav_logo16.png
If you load the MAFF file (or the index.html file in the unzipped version) back into firefox it renders page as it was when you saved it. Even if you are offline, and the original website is down. If it did not do that then the whole proposal is vaporware. Luckily for us that worked in the test we did.
Storing the snapshot in Source Control
For our 'instant search' for Martin Fowler
I post-process the zip file to:
- unzip it
- copy index_files as is to the root folder of a working copy of something under source control
- rename as I copy the index.html file to the same root folder (giving it the name of the archive)
- post-process the renamed HTML page to remove leading blanks
For Subversion the trunk/tags/branches naming standard is not so applicable for storing UI snapshots. I might myself have 'progress' instead of trunk. It could be that you are using Selenium 2.0 to do that as part of your automated functional test suites, but the Selenium team is going to have to work out a way to interact with the browser's UI to do that.
What I have with this now is the ability to save the progress of the development of the website. With some more scripting I could make a movie of evolution of the web page.
Source control is the main reason we are using the broken-out files, rather than the MHTML format that the MAF plugin also supports. The problem with that format is that resources are combined into the same source file making it much bigger. Thats not a problem for some people of course, but there diffs will contains lots of noise which would be unacceptable to me.
Diffs are also the reason I'm essentially un-pretty-printing the HTML that I'm pushing into source control. Indented HTML will make for lots of noise in a diff for the current generation of SCM tools.
Python script to unpack the zip and do post-processing
To read the contents of the MAFF archive, and make them suitable for pushing into source control, I have a Python Script. It does steps 1 through 4 above:
UI designer's weapon of choice: Firebug
Consider a new story: "Remove 'other services navbar' from top of search page while Instant search for Martin Fowler is in progress" (yes, it is contrived, and yes it is even further away from good story language). This is what that would look like:

If we load up the previous saved 'search results for Martin Fowler' page in Firefox, we have our starting position for the UI change. If I then launch Firebug and locate the div for the bar in question and zap it, I have the final visuals for this. Going through the save cycle again saves the final state of the page, and it will load and look as we would want. The above change is an easy operation in Firebug of course, and is barely worthy of a mockup before coding. You get the point though; I am trying to suggest a workflow for a designer, that is based on the working product to date.
For an Agile project, you hope the customer is sitting next to you so that you can model the proposed change. For high cost customers, you are going to have a proxy for them, but sitting next to the UI expert while the designer edits the UI is core to the proposal.
This way of evolving UI would only fit Agile development techniques, as there's always "working software" to base changes off. Also each proposed change (story) is likely to be an achievable delta over what was there before. Waterfall would only have a working web-app after many months of analysis/requirements/specification/coding/QA and those folks should stick to Photoshop imaginations of the future.
There are many Firefox addons that could be used for design changes within the page. Here are a reasonable subset: Web Developer DOM Inspector Color That Site! Pixel Perfect Styles Tuner EditCSS Browser Turns Editor Platypus Codetch Font Replacer SourceEditor XUL Gear
Using branches for stories
Where to store that proposed UI change though? The answer is a branch of course. You would have one branch per story. The branches will feel throw-away over time, as all you are ever really going to do is:
- branch from the latest 'progress' snapshot of the web-site
- find the page (there could be multiple versions of the same page depending on the flow that was trying to be demonstrated).
- edit it and commit/push the changes back
There are some subtle differences between Git and Subversion in respect of storing potentially fat repeating sources like images. Git only stores each item once in its repository. It will go to a lot of of effort to recognize an item as identical to another with a different name in a different branch, and only store another reference to it. Subversion will try to do the best thing when you make a lightweight branch. However if you try adding things again in different branches with different names, it will not be some economic with respect for repository bytes. Its a small difference though, both are viable.
Persistent viewing of UI snapshots
Subversion, for free, will serve up content on trunk or branches. Unfortunately that's not in a way that's amenable to in-situ functioning of a web page. For example this - http://svn.codehaus.org/paranamer/trunk/paranamer-distribution/src/site/resources/ParaNamer.jpg - is served by Subversion, but is not a jpg that can be in-line shown in Firefox. My Codehaus buddies would have to reconfigure Apache to add back mime-types to served resources. I have mentioned that before for my Cozmos side project. It is not so hard to do.
{kind=link}
Sadly for Git there's nothing built-in that is good enough. Bart Trojanowski has made a CGI script for Git that is half way there. I am not sure it adds mime types though, and it only serves 'master' and not branches. Still it is a demonstration that it is possible to live serve from a Git repo. There could be other ways of doing the same though that were more cron-lazy-branch-and-cache centric suggested by a colleague Cosmin Stejerean that would work with Apache or Nginx.
I am really excited about the persistent online viewing of stories (whether pending or completed) because it will allow me to link from Mingle to proposed UI changes. It will also allow emailing of URLs to the business, who may or may not be interested in Stories per se, but certainly are about how it looks: no more fat graphical attachments going back an forth.
Saving something other than HTML
Luckily for us Firefox saves the final state of the HTML and resources mounted into the DOM. Google Instant is a good tool to trial this idea with as it is very interactive with the backend. Google Trends, for now, even shows that Google has trouble keeping with their own turbo-charged ajax "instant" search. Therefore using Google Instant (search) is a good way of proving that this proposed UI prototyping technique.
Would it be better though if the DOM were saved in some non-HTML way? Something like a JSON representation of the DOM? Or a series of JavaScript mutations to the DOM that yielded the same outcome?
We still have hopes that the diffs between the revisions would be terse, which means it could not rely on indentation. We also need developers to be able to understand the format so that they can reuse the achievements of the UI designer's story branches to change the applicable template page files in the app-dev trunk when the implement the stories.
So for now, maybe left justified HTML source is best. It minimizes the diff between revisions, and is directly reusable.
Snafus
A file called ab5cdb1806fef4aa.html is one of the resources saved in the Google-search MAFF that we have been playing with. It is in each of the different MAFF files saved in our hypothetical flow. Unfortunately its contents are different each time. If we're saving many MAFF files to the same source root and hoping for them to share resources, then we would want referred resources to be uniquely named. That would mean code changes to guarantee uniqueness for your own situation.
An apology to UX folks
ThoughtWorks has User Experience experts who will be quick to tell me that UI is not UX. The latter is what we think customers should be buying and not 2D screenshots of course. Thus this proposal still falls short.
Sept 14th, 2010
(thanks to Mike Long for hearing me out first time, and finding the MAFF plugin (when I thought there were none), and Cosmin Stejerean for working through the implications for Subversion and Git, and helping complete the Python script)
May 1st, 2012
The Chrome team have made an autosave plugin that looks interesting.