Paul Hammant's Blog: GeoJSON mashups and GitHub
Not new news, but GitHub are rendering GeoJSON files as a visual and interactive experience when navigating source for a project. A blog entry from Mapbox and another from Universal Mind say it best.
I do love open data backed by source-control, very small data sets, and a concept called maintained divergence, which comes into play for this (towards the end of this article).
Citizen maintained geo data
What GitHub offers is the ability for people to see a map, determine it’s wrong or could be better somehow, and through the fork, change, and pull-request cycle contribute back changes to the project’s maintainer. A pure wiki would be easier, but there’s a superiority to source-control that’s key here. Key to source-control as the backing store, is the ability for people or groups to maintain diverged data.
As an example, here’s a community radio stations uploaded to GitHub by the FCC, zoomed into New York, and displayed through the Github interface:
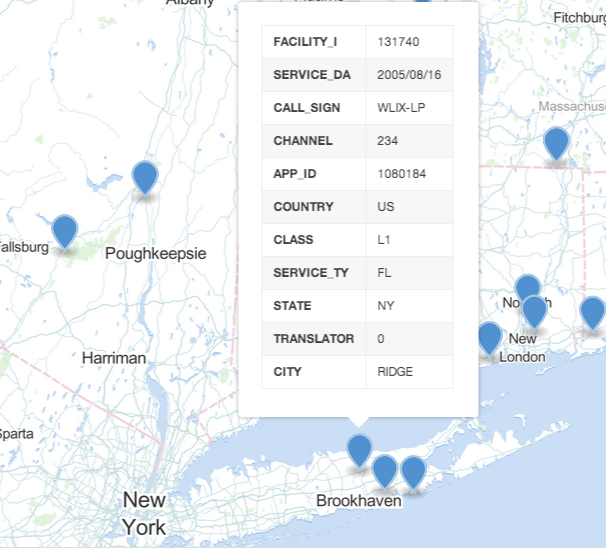
That’s screen-shotted from GitHub
Here’s the GeoJSON for the particular node i’ve zoomed in to:

If the FCC uploaded that base to their repository FCC/lpfmpoints, some actual listeners could have a fork of that repo, and enrich info for nodes. Perhaps with text clipped from the WLIX-LP website:
e.g.
{
type: "Feature",
properties: {
CALL_SIGN: "WLIX-LP",
blurb: "A wonderful mix of easy favorites without all the nonsense and chatter, that will make you smile and help the workday fly by! Songs that you remember, but have searched the radio dial in vain.. until now!<br/><br/>Easy Listening Is Cool Again! Artists that need no explanation.. Barry Manilow, Carole King, The Doobie Brothers, Marvin Gaye, Fleetwood Mac, Abba, Paul McCartney, James Taylor, Hall & Oates, Faith Hill, Bread, Simon & Garfunkel, The Carpenters, Mariah Carey, Chicago, Elton John, Celine Dion, and on and on..."
},
...
}
You will note that I have left out the stuff that does not vary between this fork and the original. I’ll come back to that later.
We could also be a little critical of the source format in that “WLIX-LP” feels like a data field rather than a key field. That type of thing makes an JSON-path from-root reference to the node in question hard.
Real world usages
I’d like to see data sets pitched at consumers and citizens, but held in source-control. I live in New York now and they have a law that means that supermarkets can’t sell liquor. I like a scotch, and it’s incredibly expensive here, so I’d like to find the cheapest places for it. There would be no better solution that to see a map (on a phone), and to be able to switch data sets to “Cheapest NYC scotch” (the source for that could be paul-hammant/cheap-manhattan-scotch on GitHub), and see the map optimized for me working out how far I want to walk, bike or subway to that cheaper scotch. Of course that’s a bit of a #firstworldproblem. Scotch is expensive due to New York’s arbitrary liquor laws, and taxation.
Here’s what the JSON could look like in a “Scotch” scenario. The “root” repo (say super-lush/manhattan-grog on GitHub) would have have all wine/liquor stores for Manhattan:
[
{
id: "Astor 399 Lafayette",
name: "Astor Wines",
location: "399 Lafayette St, New York, NY 10003",
mail-order: true,
properties: { ... },
geometry: { ... },
...
},
{
id: "Duane Reade 4 W 4th",
name: "Duane Reade",
location: "4 W 4th St, New York, NY 10012",
mail-order: true,
properties: { ... },
geometry: { ... },
...
},
...
]
My forked repo (say paul-hammant/cheap-manhattan-scotch on GitHub) inherit all the attributes from it’s parent, but subset to just scotch outlets with, with some additional price-range data:
[
{
id: "Astor 399 Lafayette",
johnnie-walker: {
min: 28,
max: 290
},
...
},
...
]
Someone else could fork mine (because I did the work subsetting) into, say, bluejw/just-blue, inherit all the attributes, but drill into the price for Johnnie Walker Blue Label specifically:
[
{
id: "Astor 399 Lafayette",
jonny-walker-blue-label: 290.50
},
...
]
I would not merge commits back from bluejw/just-blue into paul-hammant/cheap-manhattan-scotch, nor would super-lush take my commits back the super-lush/manhattan-grog repo. I would infrequently merge all (noting maintained divergence) from that root into mine, but mostly to note new outlets. Changed store-level data may or may not be acquired through merge. Dropping nodes that the parent has, could save space in the child repo (as I have shown above), but why bother really.
Citizen use instead of Consumer
There could be citizen solutions too:
- DMV locations (including subjective wait times)
- Intersections where you’re plagued by detestable Jake-Braking noise 24/7
- Precise entry/exit layouts for Manhattan subway stations
Basically, anything that could be curated over time, and held independently of Google for common good. Even differences of opinion could be catered for - someone could fork paul-hammant/cheap-manhattan-scotch and add their own opinion. The iPhone app I image would allow user configuration of which sets of geo data a person wants shortlisted or cached.
Enter CCS
JSON though better than XML is rubbish for merging though. And to maintain divergence you’re going to need merging to work as multiple forks sets grow or get refined over time.
A better format (for storage) would be CCS which allows resources to refer to (and overlay) each other in a root-branch-leaf way, but otherwise specialize as you move leafwards in a sequence. The documentation for the concept is here by Matt Hellige (one of the leads for the technology). In that README, as you come across “config file format” change that to “data format” in your head.
Matt has some examples that show off the differences between it and JSON. Matt commented in email a couple of months ago:
“I think CCS could be a good fit for other data representation needs, but only under certain circumstances. If you take a step back, the basic approach of CCS is to view configuration as a tree annotation problem: program runs implicitly describe instances of some class of trees, the nodes of which need to be annotated or labeled with these arbitrary configuration values. So the CCS language is, ultimately, a tree annotation language.
(And incidentally, as a tree annotation language, it has some nice properties, but there are other nice properties you could wish for that we don’t have. I think tree annotation languages are unfortunately rather poorly studied, so this is a design space that isn’t very well understood. But even so, it’s a good way of thinking about configuration and even if you don’t like the particular choices made by CCS, I think you could get a lot of mileage out of the approach.)
Anyway, if you have other data representation problems that feel like or could be reduced to tree annotation or tree labeling, CCS could be a great fit and would surely be worth trying. More generally, it could be used as a sort of simple monotonic inference engine, although it’s not really designed for that. For other data storage purposes, I’m not sure it would really work well.”
So a terse “tree annotation” format that works well in a source-control merge cycle is what I want. JSON isn’t close enough, and CCS is the best I can find for now. But the iPhone application I talk of would also need to somehow process that tree of CSS into a final form, and then transform that into GeoJSON for display/interaction purposes. That would be easy really, but the difficulty would be mapping in-app corrections or modifications to data (by the end user through the interface) back to the correct .ccs file in one of a short list of contributing Github repositories. That’s solvable too, I guess. I’d like to see the data first, and watch as competing phone apps roll out increasingly impressive features, as we liberate and organize this data for the common good.