Paul Hammant's Blog: Legacy App Rejuvenation
I led a group of ThoughtWorkers at a trading division of a US bank for nine months in 2005. We were called into to help improve test coverage, but the mission quickly called for more than just that. Their development team was very capable, but bogged down. What began was a “legacy-refactoring” project. The complication was that the bank didn’t want to take a time out from the delivery of functionality to production. We were asked to design something that could concurrently rework their build-infrastructure as well as continuing to push production without delays. Quality too, was not allowed to drop.
Notes:
- This was not Continuous Delivery, as nothing was being auto deployed anywhere. It was a nascent DevOps piece, that aimed to increase developer throughput.
- These events were seven and a half years ago. (I’d rather post late, than not at all)
Changing Everything At The Same Time.
Here’s what we did concurrently:
- ClearCase source-control tool to Perforce
- Trunk-Based Development (TBD) instead of feature branches
- Longer Ant build scripts changed to smallest possible scripts using templates/macros
- Monolithic source tree to modular/recursive build in a monorepo
- Multiple singletons to a single service-locator class
- Retrofit of tests, and tracking coverage
- Adding of Continuous Integration (the old CruiseControl tool)
- Service-locator to Dependency Injection
We never had time to oversee #8, as it required the completion of #4 before it could start.
Here’s a Gantt style view of the changes (say for the sake of argument there were 10 teams, but we’ll represent just four):
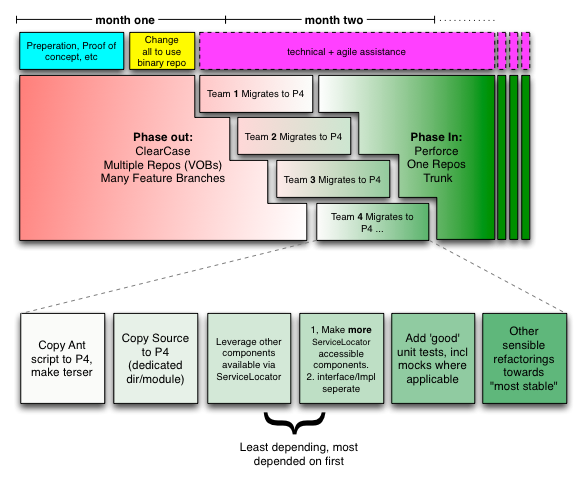
We had advisers of course. One of the department’s architects enriched our knowledge of the entanglement of their system, and pushed us hard to implement the plan. We also had the counsel of a few of the senior managers within the department who wanted to see things improved. Lastly, halfway through, the bank filled some of the vacant missing director positions above us (head-hunting takes time). These fellows acclimated quickly, and endorsed the changes being made.
Details as follows:
What we encountered
They were using ClearCase for source-control, and had one big Java source tree regardless of how many JARs would be made. There were dozens of branches that were long-lived. Each had code on them that was either intended to go live, or was valuable somehow and would prevent the branch from being deleted. Ant scripts were in use, and the dev team for each component had their own one. Each script set up a few binary dependencies before making the JAR, WAR and EAR files (as appropriate) for whichever piece of the J2EE solution it for. Globbing was used to reduce the big source tree to the JAR required. There were a few circular dependencies in there, but having all source in one compile phase allowed for that.
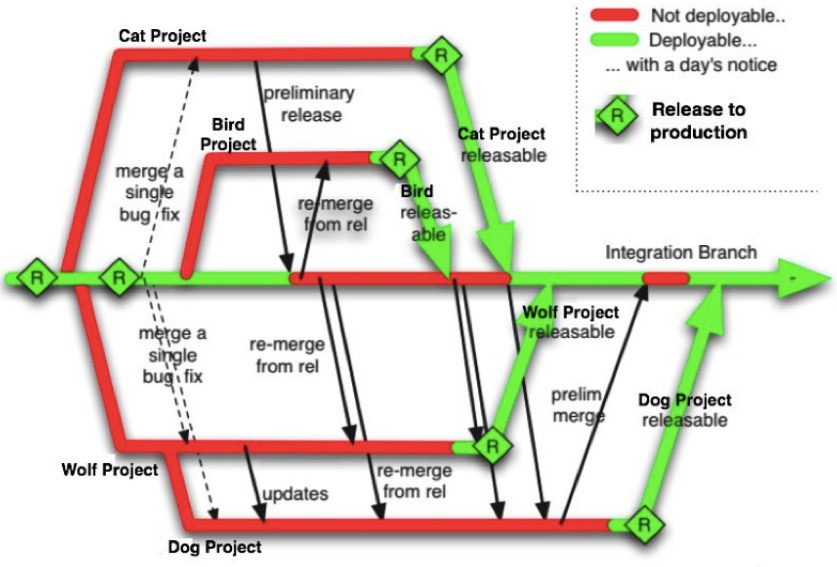
As was standard practice at the time for ClearCase enterprises, releases went out from the branch the code was developed on, then merged back to a mainline, where other teams could merge it out again to their in-progress branches. This was ‘Feature Branches’ as Martin wrote later.
The dev team (who were quite capable) wished their code-coverage was higher. It is possible that the coverage was low because the lack of clean separation of components, the presence of shared static state, etc.
Safely changing everything at the same time
Source-Control should be fast.
ClearCase was a regular choice for enterprises. It has two classic modes of operation: Dynamic and Snapshot. The former mounts a virtual directory structure similar to a network mounted Windows drive. Either way, is slow. It always has been slow, and as a result, its ‘experts’ have sophisticated branching models to make it work. Long-lived feature branches and ‘late’ integration are common. I’ve a huge problem with the risk that’s represented in long-running branches, and late integration. I always have had.
Nearly everyone at the bank was using Static/Snapshot checkouts. This used a real C-drive directory, but was a very slow checkout. From scratch that was 45 minutes. When doing an ‘update’, it was perhaps 30 minutes whether or not there were any changes. The build duration was as you’d expect for source-tree on a C: drive.
Only a couple of the developers used Dynamic checkouts. This was instantly connected to a more ‘shared’ place and thus checkout/update were faster. The downside was that the build was inordinately slow, meaning you by habit did a lot less builds in a day.
ClearCase is very dependent on the nature of the LAN in an organization. This is because it is (or was) very chatty on the wire. Perforce is a lot faster. It has been designed to work well for situations where the server and the clients are separated by 8000 miles. For the record, Git is faster still, especially when you consider that it’s bringing down all history when cloning.
Once checked out, Perforce’s speed can’t be beaten. Specifically the ‘update’ speed: you already have working-copy, and are asking for ‘latest’. Say you go to lunch, and come back and ask perforce if there are any updates for your checkout, Perforce will answer inside of a second typically for the “no changes” scenario. This is because Perforce already knows the answer, as its server side keeps knowledge of current your checkout in RAM. Perforce gets dragged into the modern age with the Fusion tool that integrates Git for local
We piloted Perforce for the first identifiable project/component/service/buildable-thing. We found the most-value branch in ClearCase with the most current “Foo” component/service and snipped it out after adding it to Perforce in a modular hierarchy (see below). “Foo” got a couldn’t-be-smaller build script, and for the right Ant target pushed it’s binaries to a shared folder like Foo-TRUNK.jar
Initially Perforce was on a Dell machine under a desk, in the “agile area” the ThoughtWorkers had reconfigured. There’s something about the wire protocol of Perforce that makes it perform in slow networks. There was some pressure from other teams to accelerate the rollout of Perforce before a decision was made to use it in an approved way.
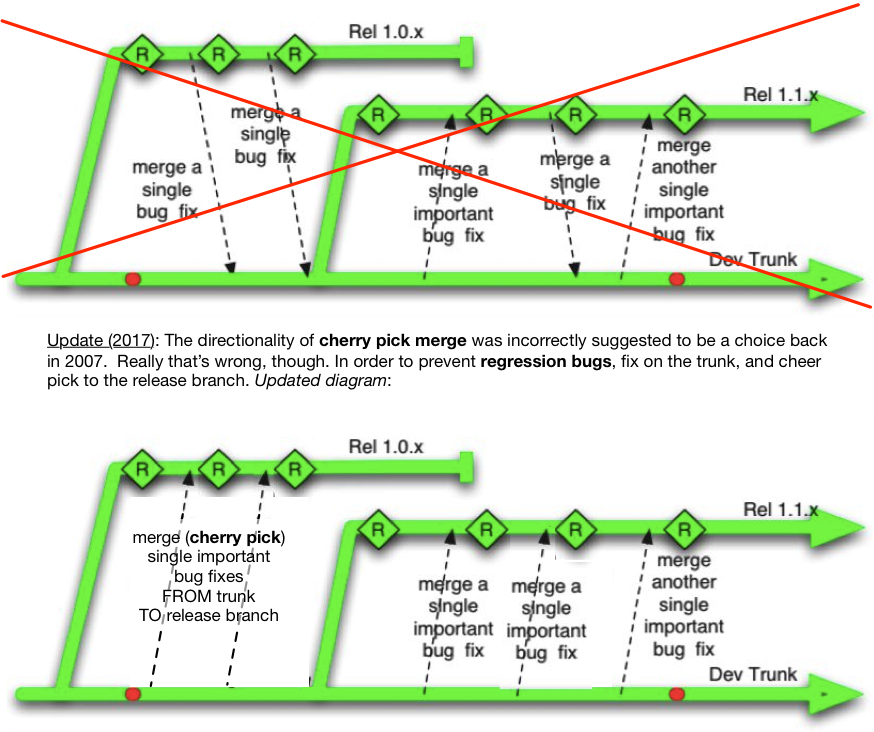
Trunk-Based Development (TBD)
In terms of source control practice, we advocated for a “Trunk” model that the open source community had been using for many years. Branches, were for releases. We had a single BUILD.properties file in the root of the trunk that contained the version number. In the case of the trunk that version number was “TRUNK”. For release branches, after the initial branch it was changed to “1.3” or whatever was applicable. If all the Ant scripts followed the same design, they’d make binaries with a single coordinated version number in it. There was a moment there on a pristine release-branch checkout to catch anomalies.
Here’s some before and after branch diagrams from my Branch by Abstraction blog entry, which was an earlier publication out of this mission. First multi-branch, as it was in ClearCase:
And a ideal trunk model, as it would become in Perforce.
Branch by Abstraction & Feature Toggles
Bigger changes were controlled by “off and onable” toggles. The off-and-onable catch phrase was borrowed from a UK TV advertisement for electric home heating. There was a second Brit on the team, and he was amused too. In order to avoid feature branches for changes that would take days or weeks, a toggle would control which of two implementations of an idea would be turned on for a running instance of the stack. I wrote about this in my Branch by Abstraction blog entry (2007).
Mentioned later in ‘baby steps’ use of toggles would handle changes from one technology to another. One was changing the implementation of a message-bus, and the other was about how messages within that bus were marshaled. The toggle controlled alternate ‘old’ versus ‘new’ implementations of each. Each of the two toggles was independent of the other.
Martin Fowler wrote about toggles later in his Feature Toggle bliki entry. Toggles is, of course, a technique within a TBD design that adds value.
As an aside, in the branch by abstraction blog entry I talked of a hypothetical migration from Hibernate to iBatis (now MyBatis). Recently a ThoughtWorks team steering the development of our story-tracker ‘Mingle’, did the exact opposite. A couple of years ago, colleague Jez talked about that in his article on Trunk/Branch-byAbstraction and Toggles.
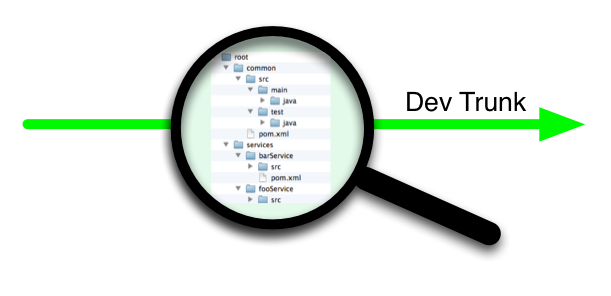
Modular, Recursive Build
The various components of the application, would be in a directory hierarchy that subtly reflected their build order and dependency. Previously they were co-mingled in a single source tree. In the new world, the build should recurse into directories where separate buildable jars are self contained with their build script. This is a Maven-like style, but back then we elected not to use Maven itself. It was also a monorepo, in that one repo had many separately buildable things, evn if CI elected to build recursively from root.
Smallest Build Scripts
We stuck with Ant rather than migrate to Maven. The latter was only just starting to become acceptable in the enterprise back then. We reduced multi-page scripts to something that could not be any smaller. Leveraging macros was the way to introduce the uniformity and elegance. If one team were to look at another team’s ant script, then they would so a lot of similarities.
These days for Java solutions, your regular choice is Maven. Perhaps you’ll choose Gradle if you’re trying to push the bar a little, and go back down to “couldn’t be smaller” build scripts.
Service Locator
“Foo”, like any of the buildable things that migrated out of ClearCase and into Perforce, had to change look up its dependencies in the Service Locator. The “from” state was singletons. Specifically the singleton design pattern, and that has to be called out because Spring and Guice have a @singleton annontation and scope which is different and confuses the matter. That was the rule. It meant that there was a programmatic place that the old world and the new world could cooperate on for the sake of dependencies. The second place they must cooperate on was the binary repository (maven-like).
Least depending, most depended on FIRST.
As a general rule, things that were least-depending and most-depended-on were the best candidates (a large graph of singletons) to be teased out of the single source tree (spread over multiple branches). Once one had been done, there was another logical candidate for most-depending and least-depended-on. Easily identifying which one that was made me help kick-off the Google Singleton Detector to visualize the entanglement for future projects.
In 2008, I wrote about the methodical ‘Dependency Injection via Service Locator, with least depending and most depended on first’ way for InfoQ e-zine: Drinking your Guice too quickly. See that article for pretty pics of entanglement. Indeed, it was writeup of this bank’s project. [Update] Since then, I’ve rewritten the same article (fixing issues, making it clearer).
Cruise Control (Continuous Integration)
We had Paul ‘PJ’ Julius on the team. He is one of the leads for the Cruise Control (Java) project. We hypothesized that if we were checking in fragments of cruise-control script for each module, then we’d need to improve the <include/> mechanism of Cruise Control to be more robust than it was. To me, continuous integration config is best held under source control adjacent to the build script for the same module. Cruise-Control would reconfigure the build when it encountered updated config files in the branch in question.
Under Source-Control?
Back then, Cruise-Control had no UI for editing CI config, but if it did I’d want it to be perfectly compatible with the use of Source-Control as the backing store. Indeed that’d be the trunk/branch as the co-located build file and source tree.
Jenkins is the CI gorilla in the room now, but it does not ordinarily co-locate its project configuration in source control. ThoughtWorks Studios has a product ‘Go’ that can have a configuration that stores such info in source control, and there is a plugin for Jenkins called DotCI made by GroupOn.
Other Tools/Techniques
The advocacy for change required many ‘lunch and learn’ sessions. One of the pivotal ones was “Refactoring code featuring TDD”, where Paul Julias showed Intellij moving code around like wet-paint while doing checkins to a co-located Cruise Control. We even had a build light in the conference room if I recall correctly. The surprise outcome was not interest in Perforce, mocking techniques, or TDD per se. Instead it was “where can I get that IDE you were using?”. A distant second in terms of interest was Perforce and whether we could sneak teams into it, before an agreed adoption by the organization.
Baby Steps
There was an ‘trade object’ that was serialized by plain Java-Serialization. It was to be pushed around a message-bus. At the architecture level the decision was made to go to XBeans, which required some design work. As a facilitating step, we persuaded them to use XStream (a ThoughtWorks / Joe Walnes open source product). We suggested a quick win could be had from going there, and the XBeans migration could be delayed to much later. There was a real cost saving made by getting to XML sooner. They ended up fine-tuning XStream to reduce the size of the trade, staying with that choice long past when we left that client, and ultimately getting the size to 173 bytes.
Along the way, they discovered that a programmer had previously put in a static reference to a server instance variable. Not a reference to a POJO designed for serialization, but a server reference with more reference to other server objects. That was totally unintended. When that was serialized via Java’s binary serialization you couldn’t see why the byte array was so big. The shift to XML (via XStream) allowed humans to see what was wrong quite easily. That might have been the root cause of the whole problem for them. In other words, the root cause of the quest to change messaging technologies (see below too).
Coupled with the trade serialization on the wire, there was a desire to change message-bus technologies. The client was tired of JMS and wanted to move to Tibco. This one was done in baby-steps too. Branch by Abstraction came in to play (see above). First the abstraction for the messaging technology was created and pushed in. Then, the second implementation was started (and unit/integration tested). The toggle for this was “off” for everyone other than the team that were working on it. Woe-betide any that would commit the same toggle to “on” before it was ready. The final step was to remove the old implementation, and potentially even the abstraction. As it happens that series could have spanned multiple releases.
After we rolled off
A health check a year later
One year later, I was summoned back on my own for a day. I wasn’t sure what to expect, but it turned out that the team wanted to present how much they’d achieved without us, and see if it matched the suggested roadmap. Much was discussed, and all I could do was approve the choices made, in our absence.
Dependency Injection
The Service Locator migration facilitated a second phase, which would moving all the Service Locator lookup to constructor injection. Of course my preference back then would have been PicoContainer which I was co-creator of. I’d spent some time selling Constructor Injection in a lunch-and-learn sessions, but ThoughtWorks left the mission before that phase started and Spring was put in instead. Spring was quickly becoming an enterprise norm in 2006.
Fast-forward half a dozen years
Through acquisition, they gained an alternate solution for the same trading platform, and at the exec level it a formal migration to that was decided. Various pieces of both systems still exist and new ones are yet being developed. A sizable chunk of the legacy platform will continue to exist for the foreseeable future and there is still active development there. Perforce and TBD are still the way to work for that platform. The unit, integration and functional tests are still there, with a high coverage, and nobody has added singletons back. Manual testing cycles are greatly reduced, with benefits for low-pain pushing to production.
Mar 11, 2013: This article was syndicated by DZone