Paul Hammant's Blog: Call to Arms: Average Story Sizes of One Day
Synopsis: Story sizes should average as close to one day as possible1. If they don’t your Agile project is going to be harder for nearly everyone involved. If your average is significantly greater than that one day, then change something until you get there. Change technologies if you have to, or split stories, or eliminate NFRs (or delay them). Of course, I assume you know what ‘Agile’ and ‘Stories’ are. So, I’m hereby calling on PMs and BAs to do their part to help developers live in this zone (details below).
A week ago, I talked about the Glass Ceilings in Application Development and that’s generally applicable to this topic too. But this blog entry is concerned with the costs of having longer estimates. Developers cannot estimate longer stories accurately. It is just impossible to consistently go above that and be accurate.
So what was intended for Agile/XP when all this stuff was new (and projects were smaller)? I suggest (synopsis) that the XP pioneers said “we can’t tell you how many iterations it is going to take, or what the final cost will be, but we can commit to shipping software in iterations, concentrating on business value, and giving you moments where you can choose to complete, pause, or abandon development of the product/service”, and to that end, they envisaged smaller than 3-day stories.
What to do if you have longer averages?
What if you average is significantly longer than that one-day mark? What if it is, say, 3 days with the increased risk to measured progress and team morale? Work out what is wrong, and change it, is the answer.
Spoiler: You either have the wrong people, or the wrong technologies, or stories imperfect
for development to start, or poor development infra, or odious non-functional requirements.
Wrong people?
It could be that you could change the developers for the project. Developers are the biggest percentage of resource costs when considering the price of a story. Say you have a project that uses Hibernate, you may get a boost from hiring Gavin King (who is/was the Lead Developer for Hibernate). He may not thank you for plucking him from his yacht, but he really knows that stuff. How much can be gained from having experts on those technologies which are just part of a larger stack? How much faster are the experts versus good generalists within the team? It seems that perhaps only modest gains could be made, and as you implicitly lose the generalists, you lose the blended-team productivity benefits.
Wrong technologies?
Maybe the technologies are wrong. Following on from that topic from a week ago, I suggesting that we can, unfortunately, choose technologies that really make it hard for us to complete what were trying to do. Here’s an example: Hardy Leung has made the excellent Tagxedo.com site. It is mostly HTML of course, but a critical design tool for word clouds is written using Microsoft’s Silverlight technology. Hardy might have started with a HTML site and quickly imagined an eternity of effort to get his vision complete. He settled on Silverlight for the best ‘bang for the buck’, and having used the app on my Mac, I can say that he has done a great job. Near the bottom of his FAQ he goes into his rationale for choosing Silverlight. That is one of a few ‘right’ technologies for this job, as of Q2 2012.
Changing technologies is not cheap of course. Sometimes you’ve gone too far to change, and it’s better to soldier on. Quickly identifying the need to change is best. Perhaps best of all during the ‘experimenting with technologies’ phase before ramping up the project. Again, be careful not to choose one with glass ceilings.
Rule of thumb - 100 Lines of Code
For the technologists amongst us, critically estimate the number of lines executed (non-framework, non-library) from the ‘click’ the user did all the way down the stack and back up again for the response that changes the UI. That counts JavaScript, Java, Ruby or C#, and stops at SQL. If you’ve busted the facade pattern, then count all those tendrils down the stack. That is, unless your client caching strategy can massively mitigate2 that. Aim at a max of 100 lines executed. If you’re not hitting that, ask for simpler technologies in order to be able to hit the one day story average.
If you are looking at your code and note that it is longer than that 100 lines max for a page rendering, but that code is otherwise ‘good’, try to identify whether there’s a library you could extract. If the business logic of your app is removable/pluggable, then it could be a great idea to extract that framework/library. Open Source is ideal, because in order to meet an implied goal of pulling in external collaborators, you’ll need to make it buildable, provide decent test coverage, and have copious examples if your tests don’t stand as perfect examples of use. That, and a meaningful release strategy, and a willingness to attend raised defects and user-community postings.
Story analysis wrong?
Perhaps the stories do not adhere to the Extreme Programming ideals of thin vertical slice or the INVEST principle. That spelled out is “Independent, Negotiable, Valuable, Estimable, Small and Testable”. Perhaps before estimation more representatives of the development team can advise on where to make splits in stories, and the Business Analysts still have time to rework them with the customer’s agreement before that estimation session. These should be outliers though. Story splitting I mean. A team that is zipping along will be feeding developers stories where the sizing is optimal, and if they are too large (from somebody’s perception) they can’t be split any further, and something else is ‘wrong’. I’d never like BAs to just accept the large-story scenario though; I’d implore them to respectfully push back at the project manager, stakeholders and architects in the team to try to change something so that the one-day average could become true. If that means they have to say “it looks like our technologies are too complicated” ad they see it, then so be it.
Poor development infrastructure or approach
Maybe what the developers live with day to day is insufficient. If the dev workstations are poor, IDE usage will be slow, and local build times long. If the developers can’t run a workstation build from start through unit, integration and functional tests on their developer workstations without using shared infrastructure elsewhere, then it is not good. They should if everything was prepared correctly, be able to run that workstation build off-line (disconnected from the LAN).
Maybe the build is long because it’s doing too much ‘full stack’ automation. Where is the service-virtualization (wire mocking)? Maybe Selenium keeps closing and reopening the browser during the functional UI tests.
“The build” (to me) means on a dev workstation OR in a CI/CD cloud, by the way.
NFRs killing you?
Non-functional Requirements; Hmmm. The cost of implementing something in a technology is one thing, but Agile teams have an additional factor to worry about: They frequently revisit code that is complete to a certain level, and move it incrementally as new stories come in. That can include refactoring. So is the technology or the way you are using it friendly to refactoring? Quite often the NFRs for an Agile team mandate the least-refactorable technologies in to the mix.
CORBA
CORBA is traditionally a technology that’s not easy to refactor in the best of breed IDEs. It is bound to be an NFR, as its not often going to be chosen given free choice.
Say you have a three-tier architecture, and the architects stipulated CORBA as the RPC linkage between a service tier and its client in the same language. You might have a future requirement to bolt on a second client in a different language, making CORBA a common choice for later on in the project. At the beginning you had many technology choices. Maybe the language in question had something more canonical for it (like Ruby’s DRb). Using that might be a lot easier than crafting all the IDL that CORBA deems necessary. Perhaps you should leverage an open source library that makes for RESTful endpoints into the service tier, that is again easier to use, but with the added benefit of maybe being good enough for the future second client. Even if you ‘must have’ CORBA in that final multi-client technology version, you could have gained initial functional productivity using easier technologies and added a small CORBA layer later. I.e. delay is a good choice, if you plan carefully. There are other RPC choices that are multi-language that are also viable, and perhaps easier to deal with that CORBA: Thrift and FlowType Bridge are just two.
Persisting to a normalized database
Maybe its a requirement for a relation schema that’s been normalized to the nth degree and having referential integrity turned in with constraints and triggers. If you ‘only’ have a UI interpreting with that store, and that UI needs a JSON document to and from into today’s cheapest web technologies (AngularJS or Knockout) then why bother with the relational schema? Use a document store for the time being, and migrate to a relational schema later in the project. Read up on NoSQL people.
You might do a document-store solution for pure productivity reasons, but have a known relation schema need later in the project for operation or managerial reports. You still have choices. You could create a extract process that takes the written document data and writes it to relational tables to be used in reports. That could happen in real time, or in a daily batch extract.
Multi-tier per se.
Is it possible that you’ve got the tiers that the architecture team want for the final product, and there’s a lot of fairly predictable transformation logic going on up and down the stack to separate the models. It could be that you could gain productivity by delaying a tier separation. Perhaps Conway’s Law 3 workshops should be and yearly and mandatory for managers, project check-book holders, executives and architects with IT organisations :)
Technical-debt stories.
This is a secondary effect….
Obviously by delaying work we may end up with a number of technical debt stories. They are controversial, as the customer may not ultimately map them to features they have asked for. In later phases of the story, the customer may be used to the horse-trading stage of iteration planning and killing stories that have no business value. Finding the right way of describing what is being paid for later is key. I’ve seen such stories explained well in terms of business value. Your risk at this moment is that a huge piece of work has been delayed, and someone wants to do this on a branch over a month or more, rather than Branch by Abstraction. Maybe as you justify and decide to delay non-functional work, you have a good idea as to how you would quickly/cheaply do the right thing later on, without actually coding it.
Lastly.
Colleague Derek Hammer reminds me of one the fundamental benefits of this proposal: Consistent throughput/liquidity because ‘small’ stories are the average. There are some stats involved, but the gist is that we have less waits on stories being completed. We also have less ‘hangover’ of nearly completed stories, the points/days for which ‘banked’ in the next iteration. Here that problem in a chart form:
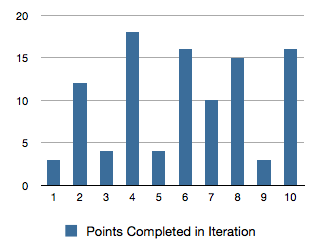
How is the project doing? What is the trend for story points per iteration? I don’t think we can’t really tell from that chart.
Updates
Feb 2, 2017: Poor development infrastructure or approach added.
Feb 6, 2023: Richard Lawrence and Peter Green have a really excellent Guide to Splitting User Stories towards thin vertical slices. Their portal being “Humanizing Work”.
Feb 6 2023: The definiton of the build has changed over time as I blogged in 2017.
Footnotes.
-
Stories have estimates and actual times. I’m assuming here that your team has these more or less the same as you get into your stride. ↩
-
Please read Steve’s Souder’s Cache them if you can blog entry. ↩
-
Thanks to colleague James Lewis for the reminder. ↩